杨荣文谈台湾, 香港, 印巴水资源战, AI – DeepSeek | George Yeo: Taiwan, Hong Kong, water resource war between India and Pakistan and AI – DeepSeek.
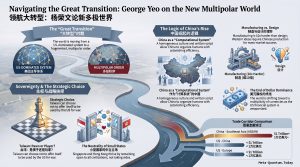
新加坡前外长杨荣文认为,中国的治国之道本质上是防御性的,而非扩张性的。谈及台湾,他预测若强制统一,约5%至10%的人会离开,其余人将像香港在2020年后那样逐渐适应。从特朗普的谈判风格到DeepSeek的开源策略,杨荣文以罕见的内部视角,描绘出他称之为"三个太阳"的多极世界图景。 Singapore's former Foreign Minister George Yeo argues China's statecraft is fundamentally defensive, not expansionist. On Taiwan, he predicts 5–10% might leave under forced reunification, the rest adapting much like Hong Kong did post-2020. From Trump's negotiating style to DeepSeek's open-source gambit, Yeo offers a rare insider's map of a multipolar world he likens to "three suns."