

Introduction
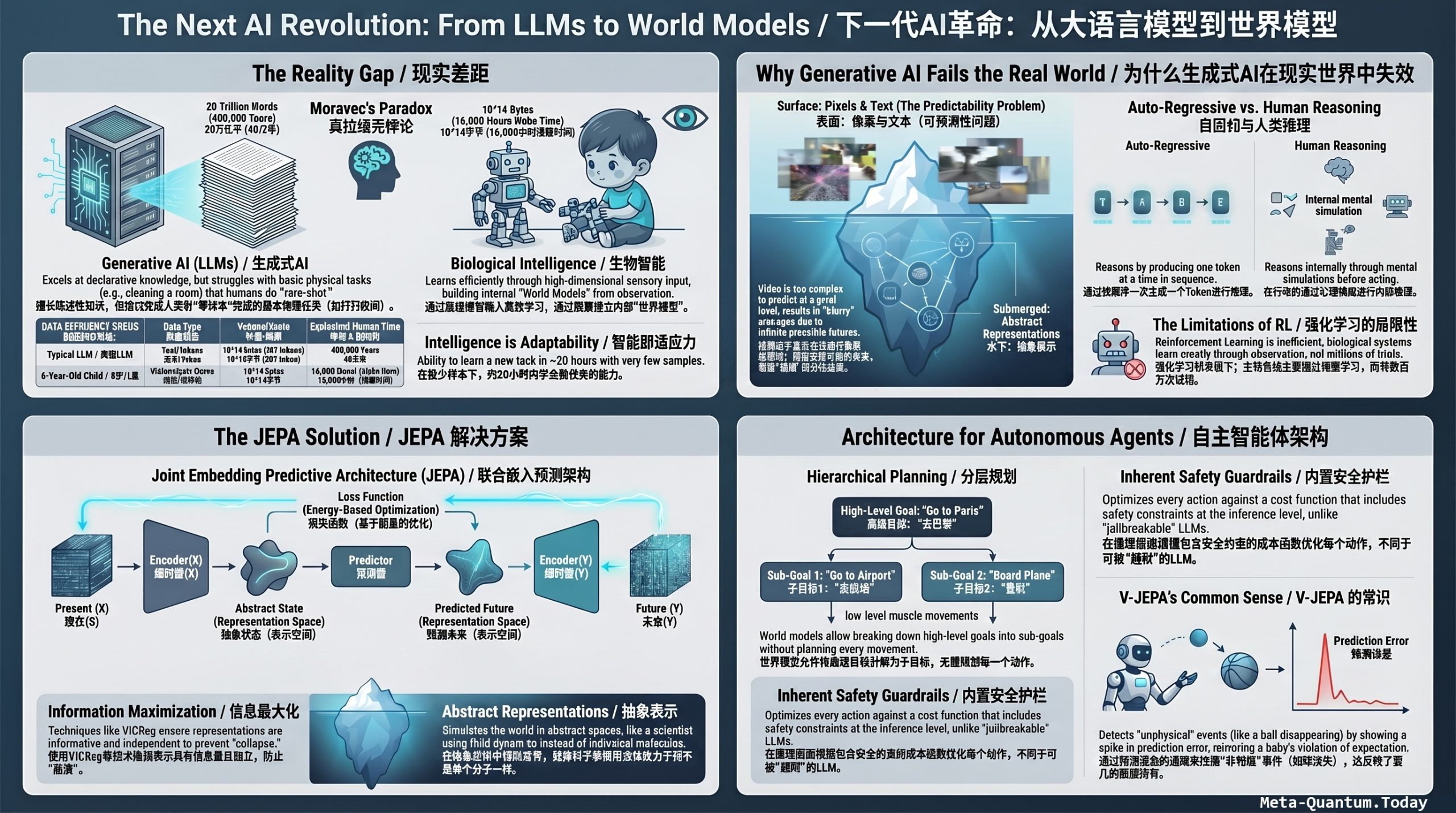
Yann LeCun — Turing Award laureate, NYU professor, and former Meta Chief AI Scientist — lays out his case for why world models, not large language models, are the path to genuinely intelligent machines. He opens provocatively (“machine learning sucks”) by contrasting machine learning with human and animal learning: a teenager learns to drive in roughly 20 hours, while self-driving companies with millions of hours of training data still cannot reach Level 5 autonomy. This is the Moravec paradox in action — language and chess are easy for computers, while the messy, continuous, high-dimensional real world remains hard. The talk also marks a personal turning point: LeCun has left Meta to found a new company, AMI Labs, focused on “AI for the real world.”
New Features and Concepts
Intelligence as adaptivity, not accumulation. Channeling Jean Piaget (“intelligence is what you do when you don’t know” — a quote LeCun notes is apocryphal), he argues intelligence is neither declarative knowledge (what LLMs accumulate) nor a collection of skills, but the ability to learn new tasks quickly with little training. On this basis he calls the notion of AGI “complete nonsense” — human intelligence itself is specialized and adaptive.
The data argument against LLM scaling. A striking calculation: a modern LLM trains on ~20 trillion words (~10¹⁴ bytes), equivalent to 400,000 years of human reading. A four-year-old child has absorbed roughly the same 10¹⁴ bytes through vision alone in 16,000 waking hours. Conclusion: human-like intelligence will not emerge from text alone. Video’s redundancy, often dismissed as a bug, is actually a feature for self-supervised learning.
Inference by optimization, not propagation. LeCun contrasts two inference modes: reactive forward propagation through fixed layers (the LLM approach, where “reasoning” is coerced by generating more tokens) versus searching for an action sequence that minimizes an energy function at inference time. The latter requires a world model — perceive the state, imagine actions, predict outcomes, optimize against task objectives. This is essentially Model Predictive Control (MPC), classical optimal control dating to the 1960s.
Intrinsic safety via guardrail objectives. Because such a system can only act by optimizing its guardrail and task objectives, it can be made intrinsically safe — unlike LLMs, whose safety fine-tuning can always be jailbroken.
JEPA (Joint Embedding Predictive Architecture). His core technical proposal: instead of generative models that reconstruct pixels (which fail because video futures are unpredictable in detail, producing blurry averages), JEPA encodes both input and target and predicts in abstract representation space, discarding unpredictable detail. All the best self-supervised vision systems use joint embedding, none use reconstruction.
Preventing collapse: SIGReg. The central challenge of joint embedding is representation collapse. LeCun’s preferred remedy is information maximization, and his newest technique is SIGReg (Sketched Isotropic Gaussian Regularization): project batch representations along many random directions, match each empirical cumulative distribution to a Gaussian via gradient signals — a theorem guarantees the joint distribution converges to an isotropic Gaussian (maximally independent variables). It trains on a single GPU with open-source code.
All about World Models, include installation, setup and config with sample cases
The Landscape at a Glance
The open-source JEPA/world-model stack today has four main entry points, each serving a different purpose:
V-JEPA 2 / 2.1 (facebookresearch/vjepa2) — pretrained video encoders. Use this when you want state-of-the-art video/image representations off the shelf, or the action-conditioned variant (V-JEPA 2-AC) for robot planning. V-JEPA 2.1 adds a dense predictive loss where all tokens contribute to training, deep self-supervision at intermediate layers, and multi-modal tokenizers for images and videos.
EB-JEPA (facebookresearch/eb_jepa) — the educational/research library. Modular, self-contained implementations going from image-level SSL to video to action-conditioned world models, each designed for single-GPU training within a few hours — reaching 91% probe accuracy on CIFAR-10 and a 97% planning success rate on the Two Rooms navigation task. This is the best starting point for learning.
LeJEPA (rbalestr-lab/lejepa) — the SIGReg implementation. This is the technique LeCun highlighted in the talk: it identifies the isotropic Gaussian as the optimal embedding distribution and introduces Sketched Isotropic Gaussian Regularization to constrain embeddings toward it, with a single trade-off hyperparameter and linear time/memory complexity.
JEPA-WMs (facebookresearch/jepa-wms) — the planning benchmark suite. Provides pretrained JEPA world models plus DINO-WM and V-JEPA-2-AC baselines across simulated environments (PointMaze, RoboSuite) and real-robot setups, with decoder heads for visualizing rollouts.
Also worth knowing: I-JEPA (images only, the original 2023 codebase) and DINO-WM (frozen DINOv2 features + learned dynamics for planning). On the generative side of the world-model family — which LeCun explicitly distinguishes from his approach — there are DreamerV3 (RL with latent imagination) and Genie-style video world models.
Environment Setup (Common Base)
All of these are PyTorch projects. A clean base that works for everything:
# Recommended: Python 3.10–3.12, CUDA-enabled PyTorch
conda create -n worldmodels python=3.12 -y
conda activate worldmodels
pip install torch torchvision --index-url <https://download.pytorch.org/whl/cu124>
pip install timm einops numpy pillow opencv-python decord
GPU guidance: feature extraction with V-JEPA 2 ViT-L runs on a single 16–24 GB GPU; EB-JEPA and LeJEPA examples are deliberately single-GPU friendly; full V-JEPA 2 pretraining is cluster-scale and not something to attempt locally.
V-JEPA 2 — Installation and Sample Case
Install
The fastest path requires no clone at all — install PyTorch, timm, and einops, then load models directly via torch.hub:
import torch
# Preprocessor + encoder via torch.hub
processor = torch.hub.load('facebookresearch/vjepa2', 'vjepa2_preprocessor')
vjepa2_vit_large = torch.hub.load('facebookresearch/vjepa2', 'vjepa2_vit_large')
Or via Hugging Face Transformers (V-JEPA 2 models are hosted under the facebook org):
from transformers import AutoVideoProcessor, AutoModel
processor = AutoVideoProcessor.from_pretrained("facebook/vjepa2-vitl-fpc64-256")
model = AutoModel.from_pretrained("facebook/vjepa2-vitl-fpc64-256").cuda().eval()
For the full repo (training, evals, V-JEPA 2-AC planning):
git clone <https://github.com/facebookresearch/vjepa2.git>
cd vjepa2
pip install -e .
Model sizes range from ViT-L/16 at 300M parameters up to ViT-g/16 at 1B for V-JEPA 2, and ViT-B (80M) through ViT-G (2B) at 384 resolution for V-JEPA 2.1, each with downloadable checkpoints and pretraining configs.
Sample Case A — Video feature extraction + action recognition probe
import torch, numpy as np
from decord import VideoReader
# 1. Load 64 frames from a video
vr = VideoReader("sample.mp4")
idx = np.linspace(0, len(vr) - 1, 64).astype(int)
video = vr.get_batch(idx).asnumpy() # (64, H, W, 3)
# 2. Preprocess and encode
inputs = processor(list(video), return_tensors="pt").to("cuda")
with torch.no_grad():
feats = model.get_vision_features(**inputs) # (1, N_tokens, D)
# 3. Frozen-backbone classification: pool + linear probe
clip_embedding = feats.mean(dim=1) # (1, D)
# train a small nn.Linear(D, num_classes) on top — backbone stays frozen
This is the canonical JEPA usage pattern: the encoder is never fine-tuned; you train only a lightweight “attentive probe” or linear head per task — exactly the “tiny projection head, very few samples” answer LeCun gave in the Q&A.
Sample Case B — Physical plausibility detection (the “surprise” test)
Using the predictor’s internal prediction error as an anomaly score, sliding a 16-frame window across a video — error spikes indicate physically implausible events. The repo’s evaluation suite includes the IntPhys-style benchmarks for this. Pseudocode of the pattern:
errors = []
for t in range(0, T - 16):
window = video[t : t + 16]
pred = predictor(encoder(window[:8])) # predict future reps
target = encoder(window[8:])
errors.append((pred - target).pow(2).mean().item())
# A spike in `errors` ≈ violation of expectation
EB-JEPA — The Best Learning Path (Single GPU)
Install
EB-JEPA uses uv for package management: run uv sync, then either activate the venv or use uv run. A conda + uv hybrid is also supported: create a Python 3.12 conda env, then uv pip install -e . --group dev.
git clone <https://github.com/facebookresearch/eb_jepa.git>
cd eb_jepa
uv sync
source .venv/bin/activate
Config
Two environment variables control paths — add to ~/.bashrc: export EBJEPA_DSETS=/path/to/eb_jepa/datasets (required) and optionally EBJEPA_CKPTS=/path/to/checkpoints for logs and checkpoints. Each example ships with a YAML config (encoder dims, mask ratios, EMA momentum, learning rate) you can edit directly.
Sample Cases — The Three-Step Ladder
Training is launched per example: python -m examples.image_jepa.main, examples.video_jepa.main, or examples.ac_video_jepa.main.
Step 1, Image JEPA on CIFAR-10: masked-patch prediction in latent space; probe the frozen features afterward (~91% accuracy expected). Step 2, Video JEPA on Moving MNIST: extends the same objective to multi-step temporal prediction. Step 3, Action-conditioned JEPA + planning on Two Rooms: trains a world model conditioned on actions, then runs MPC-style planning over latent rollouts — this is the talk’s full architecture (perception → world model → energy minimization over action sequences) in miniature, achieving ~97% navigation success. Each stage trains in a few hours on one GPU, making this the most accessible end-to-end demonstration of “plan by optimizing through a learned world model.”
LeJEPA / SIGReg — Collapse Prevention as a Library
Install
git clone <https://github.com/rbalestr-lab/lejepa.git>
cd lejepa
pip install -e .
Sample Case — Drop SIGReg into your own training loop
The minimal usage: choose a univariate statistical test (e.g., Epps-Pulley), wrap it in the multivariate slicing test with a number of random projection slices, and apply it to your embedding batch:
import lejepa
univariate_test = lejepa.univariate.EppsPulley(num_points=17)
sigreg = lejepa.multivariate.SlicingUnivariateTest(
univariate_test=univariate_test,
num_slices=1024, # random projection directions
)
# Inside your training loop:
z_ctx = encoder(view_a) # (batch, dim)
z_tgt = encoder(view_b)
pred_loss = (predictor(z_ctx) - z_tgt.detach()).pow(2).mean()
reg_loss = sigreg(z_ctx) # pushes embeddings toward isotropic Gaussian
loss = pred_loss + lam * reg_loss # lam: the single trade-off hyperparameter
loss.backward()
This is exactly the projection-and-CDF-matching trick LeCun described in the talk: project embeddings along many random directions, compare each empirical marginal against a Gaussian CDF, and backpropagate the correction. No EMA teacher, no stop-gradient heuristics, no negative samples. The augmentation recipe in the repo follows a DINO-style multi-crop approach — 2 global views and 6 local views per image at different scales. A nice independent reproduction note: SIGReg prevents collapse without contrastive samples even on CIFAR-100 with ViT-Tiny, though nano-scale models can exhibit a head-collapse phenomenon — worth knowing if you experiment at very small scale.
JEPA-WMs — Planning Benchmarks and Robot Environments
Install and Config
git clone <https://github.com/facebookresearch/jepa-wms.git>
cd jepa-wms
uv pip install -e .
Configuration is checkpoint-directory driven: set $JEPAWM_OSSCKPT pointing to a tree containing V-JEPA v1/v2 checkpoints and DINOv3 weights; pretrained models are downloadable from Hugging Face Hub (recommended) or fbaipublicfiles. Environment setup has one legacy quirk: PointMaze requires MuJoCo 2.1.0 via mujoco-py (download to ~/.mujoco, export LD_LIBRARY_PATH), while other environments use the modern mujoco package; RoboSuite is installed from a forked repo via uv pip install -e .
Sample Case — Latent-space MPC planning
The workflow mirrors the talk’s architecture directly: encode the current observation with a frozen encoder (DINOv2/DINOv3 or V-JEPA), roll out candidate action sequences through the learned latent dynamics model, score each rollout against the encoded goal image (the energy function), and optimize with CEM/MPPI. Decoder heads are available to visualize rollouts but aren’t required for training or planning evaluation — a nice illustration of “prediction in representation space, pixels only for human inspection.”
Practical Configuration Cheat Sheet
For configuration purposes, three knobs matter most across all these repos. First, masking ratio and strategy (in the YAML configs): video JEPA uses large spatiotemporal block masks (~75–90%) — too little masking makes prediction trivial and degrades features. Second, collapse prevention choice: EMA-distillation (V-JEPA, DINO style — proven at scale) versus SIGReg (LeJEPA — simpler, theoretically grounded, newer). Third, probe versus fine-tune: the entire paradigm assumes frozen backbones; if your downstream results are poor, fix the probe (try attentive pooling instead of mean pooling) before touching the encoder.
Video about World Models
Related Sections of Video
Developmental psychology as a roadmap. Babies learn the world is 3D within months purely from observation (parallax explains visual change under motion); object permanence comes quickly; intuitive physics like gravity takes ~9 months. Psychologists detect concept acquisition via “violation of expectation” — and remarkably, the same test now works on machines: V-JEPA’s internal prediction error spikes when shown physically impossible videos (a ball vanishing mid-flight), which LeCun calls the first self-supervised system to acquire a level of physical common sense. This aligns with his long-standing argument that LLM hallucinations stem from autoregressive token prediction, where error probability compounds exponentially and the system never naturally gravitates toward truth (Glasp summary).
Abstraction as the essence of prediction. Science itself works by inventing abstraction hierarchies — quantum fields → atoms → molecules → cells → organisms → societies — each ignoring lower-level detail to enable longer-range prediction. Aerodynamics simulates airflow with Navier-Stokes equations, not molecular collisions. Hence world models should not be pixel-level simulators, digital twins, or video generators: “if you want to produce cute videos, work on video generation; if you want to control robots, do not.”
Practical results. Distillation-based JEPA variants (I-JEPA, V-JEPA, DINO/DINOv3 from Meta) currently produce the best generic image representations, train faster than masked autoencoders, and support planning: a DINO-encoded world model plans action sequences in complex simulated dynamics within 25 steps. V-JEPA 2.1 representations, with a small trained head, predict depth from a single image better than DINOv3 — evidence the system “understands” 3D structure from passive video alone.
Hierarchical planning — the open problem. Using his NYU-office-to-Paris example (high-level plan: get to airport, catch plane; recursively decompose to sub-goals), LeCun stresses that hierarchical planning remains unsolved and is “a great PhD topic.” This echoes his consistent message that training world models by observation, planning with learned world models, and hierarchical planning are the key open research frontiers for robotics and physical AI (Glasp summary).
Conclusion
LeCun closes with his now-famous list of heresies: abandon generative models in favor of joint embedding architectures; abandon probabilistic models in favor of energy-based models; prefer regularized/information-maximization methods over contrastive ones; and minimize reinforcement learning (“what you do when you’re desperate”) — use it only on top of good pre-learned representations. Academics, he insists, should not work on LLMs at all, since they can bring nothing to that table. His new venture AMI Labs targets exactly the domains where LLMs are helpless: high-dimensional, continuous, noisy systems — robotics, industrial process control, physical AI. In the Q&A, he clarifies that task objectives and constraints in representation space require only tiny trained projection heads, learnable from very few samples.
Key Takeaways
- Intelligence = rapid adaptation, not accumulated knowledge or skills; “AGI” is a misnomer because even human intelligence is specialized.
- Text is a dead end for grounded intelligence — a 4-year-old’s visual input matches the entire internet’s text corpus in bytes.
- Predict in representation space, not pixel space — JEPA discards unpredictable detail, which is why it outperforms generative/reconstruction approaches for representation learning.
- Inference by energy minimization (planning via world models + MPC) is computationally more powerful than fixed-depth forward propagation, and enables intrinsically safe systems via guardrail objectives.
- SIGReg is the newest collapse-prevention technique — provably recovers isotropic Gaussian latents, simple, single-GPU trainable, open source.
- V-JEPA demonstrates emergent physical common sense — prediction error spikes on impossible events, mirroring infant violation-of-expectation experiments.
- Hierarchical planning is wide open — arguably the most important unsolved problem for agentic and physical AI.
Related References
- LeCun (2022), A Path Towards Autonomous Machine Intelligence — the position paper underpinning this talk
- I-JEPA (Assran et al., 2023) and V-JEPA / V-JEPA 2 (Bardes et al., 2024–2025) — image and video instantiations
- DINO / DINOv3 (Meta FAIR Paris) — state-of-the-art self-supervised image encoders
- VICReg, Barlow Twins, MMCR — information-maximization collapse-prevention methods
- BYOL (Google DeepMind) — origin of the EMA-teacher distillation trick
- Glasp insights: Yann LeCun on world models and robotics and Why LLMs hallucinate
