

Introduction
A wry, skeptical field report from a theoretical physicist examining “AutoResearchClaw” (also styled AutoResearch Claw), an autonomous AI-scientist system whose paper landed on May 19, 2026. The framing is deliberately deflationary: the creator opens with Sam Altman’s 2024 promise that AI would help cure cancer and even replace the human principal investigator, then cuts to the 2026 reality — a single prompt where you “drop a research idea” and the system returns a full academic paper. The pitch is seductive: real literature pulled from sources like OpenArchive, Semantic Scholar, and Google Scholar; sandboxed GPU experiments; statistical analysis; multi-agent peer review; and a conference-ready manuscript. The open-source repo (MIT license, ~12,000 stars) makes it all feel tantalizingly real.
The narrator’s core stance is that the gap between marketing (“you think of it, AutoResearchClaw writes it”) and substance is exactly what the paper’s own authors quietly admit. This tension between the autonomous-researcher dream and what was actually delivered is the throughline of the whole review. It echoes a long-running idea in AI commentary that automated researchers could one day read every ML paper ever written, learn in parallel from copies of themselves, and accumulate the equivalent of millennia of experience — a vision this video treats as still firmly aspirational.
AutoResearchClaw
A real, actively developed project — here’s the full practical picture, grounded in the official aiming-lab/AutoResearchClaw repo (the video’s “v5 / 12k stars” framing is a bit ahead of reality; the public repo is currently v0.3.1, MIT-licensed, Python 3.11+ with ~6.4k stars and 1,634 passing tests).
What it actually is
A Python framework that turns a single research idea into a conference-ready paper through a 23-stage pipeline covering literature discovery (OpenAlex, Semantic Scholar, arXiv), hardware-aware sandbox experiments, statistical analysis, multi-agent peer review, and LaTeX output targeting NeurIPS/ICML/ICLR. It can run fully autonomously or in co-pilot mode with human gates, and it self-heals failed experiments and prunes hallucinated citations.
Prerequisites
- Python 3.11+ and
git - Docker (optional but recommended for the hardened sandbox / GPU experiments) and a LaTeX install (for
.tex→ PDF compile). Theresearchclaw setupstep checks for both. - An LLM backend, via either:
- An OpenAI-compatible API key (OpenAI, OpenRouter, DeepSeek, MiniMax, Novita…), or
- An ACP coding agent (Claude Code, Codex CLI, Gemini CLI, Kimi, OpenCode) — in this mode your coding agent acts as the LLM backend for all stages with no separate API key needed.
Installation
# 1. Clone & install
git clone <https://github.com/aiming-lab/AutoResearchClaw.git>
cd AutoResearchClaw
python3 -m venv .venv && source .venv/bin/activate
pip install -e .
# 2. Setup — interactive; installs OpenCode "beast mode", checks Docker/LaTeX
researchclaw setup
# 3. Configure — interactive; pick your LLM provider, writes config.arc.yaml
researchclaw init
# (manual alternative: cp config.researchclaw.example.yaml config.arc.yaml)
The README also collapses this into a one-liner: pip install -e . && researchclaw setup && researchclaw init && researchclaw run --topic "..." --auto-approve.
Configuration
researchclaw init generates config.arc.yaml. The minimum viable config is small:
project:
name: "my-research"
research:
topic: "Your research topic here"
llm:
base_url: "<https://api.openai.com/v1>"
api_key_env: "OPENAI_API_KEY"
primary_model: "gpt-4o"
fallback_models: ["gpt-4o-mini"]
experiment:
mode: "sandbox"
sandbox:
python_path: ".venv/bin/python"
The knobs worth knowing from the full reference:
| Section | Key options | Notes |
|---|---|---|
project.mode | docs-first / semi-auto / full-auto | overall autonomy level |
experiment.mode | simulated / sandbox / docker / ssh_remote | how/where code runs; docker enables GPU + network policy, ssh_remote targets a GPU box |
experiment.max_iterations | default 10 | self-healing refinement rounds |
export.target_conference | neurips_2025 / iclr_2026 / icml_2026 | LaTeX template |
security.hitl_required_stages | [5, 9, 20] | the three human-approval gates (skipped by --auto-approve) |
llm.s2_api_key | optional | Semantic Scholar key for higher rate limits |
ACP mode (no API key — let Claude Code/Codex/Gemini drive):
llm:
provider: "acp"
acp:
agent: "claude" # or codex / gemini / kimi / opencode
cwd: "."
Two optional bridges add capability without code changes: metaclaw_bridge (cross-run learning — converts failures into reusable skills injected into all 23 stages, reporting +18.3% robustness) and openclaw_bridge (scheduled runs, Discord/Slack notifications, parallel sub-sessions, live web fetch).
Ways to run it
| Method | How |
|---|---|
| Standalone CLI | researchclaw run --config config.arc.yaml --topic "..." --auto-approve |
| OpenClaw (easiest) | Share the repo URL with OpenClaw → it reads RESEARCHCLAW_AGENTS.md, then say “Research [topic]” → it clones, installs, configures, runs, and returns results |
| Claude Code | Reads RESEARCHCLAW_CLAUDE.md; just say “Run research on [topic]” |
| Python API | from researchclaw.pipeline import Runner; Runner(config).run() |
Simple showcase
A minimal end-to-end run on a small, well-scoped methodology question:
source .venv/bin/activate
export OPENAI_API_KEY="sk-..."
researchclaw run \\
--config config.arc.yaml \\
--topic "Do different cross-validation strategies meaningfully change model selection on small tabular datasets?" \\
--auto-approve
What happens under the hood is the 8-phase, 23-stage flow — scoping → literature pull (real APIs) → hypothesis via multi-agent debate → hardware-aware code generation → sandboxed execution with self-healing → a PROCEED/REFINE/PIVOT decision at stage 15 → drafting → peer review → quality gate → LaTeX export → citation verification.
When it finishes, results land in artifacts/rc-YYYYMMDD-HHMMSS-<hash>/deliverables/, containing:
paper_draft.mdandpaper.tex— full paper + compile-ready LaTeXreferences.bib— real BibTeX, auto-pruned to inline citationsverification_report.json— a 4-layer citation integrity check (arXiv ID → CrossRef/DataCite DOI → Semantic Scholar title match → LLM relevance scoring)experiment runs/+charts/— generated code, JSON metrics, comparison charts with error barsreviews.md— multi-agent peer review with methodology-evidence consistency checks
To stay in the loop instead of full-auto, drop --auto-approve and it will pause at stages 5, 9, and 20 for your sign-off — which, per both the paper and the video, is where the quality actually comes from.
Practical caveats
It’s genuinely v0.x: the surrounding ecosystem notes it’s powerful but painful to set up — many early issues were about setup failures, config confusion, and a Stage 10 (code generation) crash, which is why a community wrapper skill (OthmanAdi/researchclaw-skill) exists to automate config and error diagnosis. Docker + a real GPU matter a lot for the experiment stages; the simulated mode is fine for kicking the tires without burning tokens or compute. And keep the video’s punchline in mind — treat outputs as a research amplifier, not a finished publication.
New Features and Concept
AutoResearchClaw is positioned as version 5 of an evolving multi-agent autonomous research pipeline, and the upgrade is built around five mechanisms:
- Multi-agent debate for both hypothesis generation and result analysis — a cast of investigator, innovator, pragmatist, and contrarian agents that argue and then reach consensus or a majority vote.
- A self-healing executor with a “pivot/refine” decision loop designed to convert execution failures into usable information rather than dead ends.
- Verifiable result reporting — explicit guardrails against fabricated numbers and hallucinated citations.
- Human-in-the-loop (HITL) collaboration — seven intervention modes ranging from full autonomy to step-by-step human oversight.
- Converting past mistakes into future safeguards — institutional memory across research cycles.
Conceptually, the most important admission is in the paper’s first sentence: automatic scientific discovery requires more than generating papers from ideas. The authors acknowledge that real research is iterative — hypotheses get challenged, experiments fail and inform the next attempt, and lessons accumulate across cycles. That reframing — from “autonomous paper generator” to “iterative research partner” — is the actual conceptual shift here. This sits squarely in the broader autonomous-agent paradigm, where the dream has long been to give individuals a virtual researcher, assistant, writer, or worker at their disposal, while reality keeps demanding more structure and oversight.
The Pipeline and How It Works
The workflow flows through distinct phases: a discovery phase (problem decomposition and domain detection), literature discovery (paper collection, screening, knowledge extraction), knowledge synthesis (hypothesis formation via the multi-agent debate), then the experimentation phase — code generation, resource planning, and sandboxed Docker execution. When code fails, a failure-diagnosis loop iteratively repairs it; when it succeeds, the system analyzes results and decides whether to proceed, refine, or pivot to a different topic. After looping (the narrator notes up to ~10 refinement cycles), the system writes the paper.
YouTube about AutoResearchClaw
Benchmarks and the Comparison Game
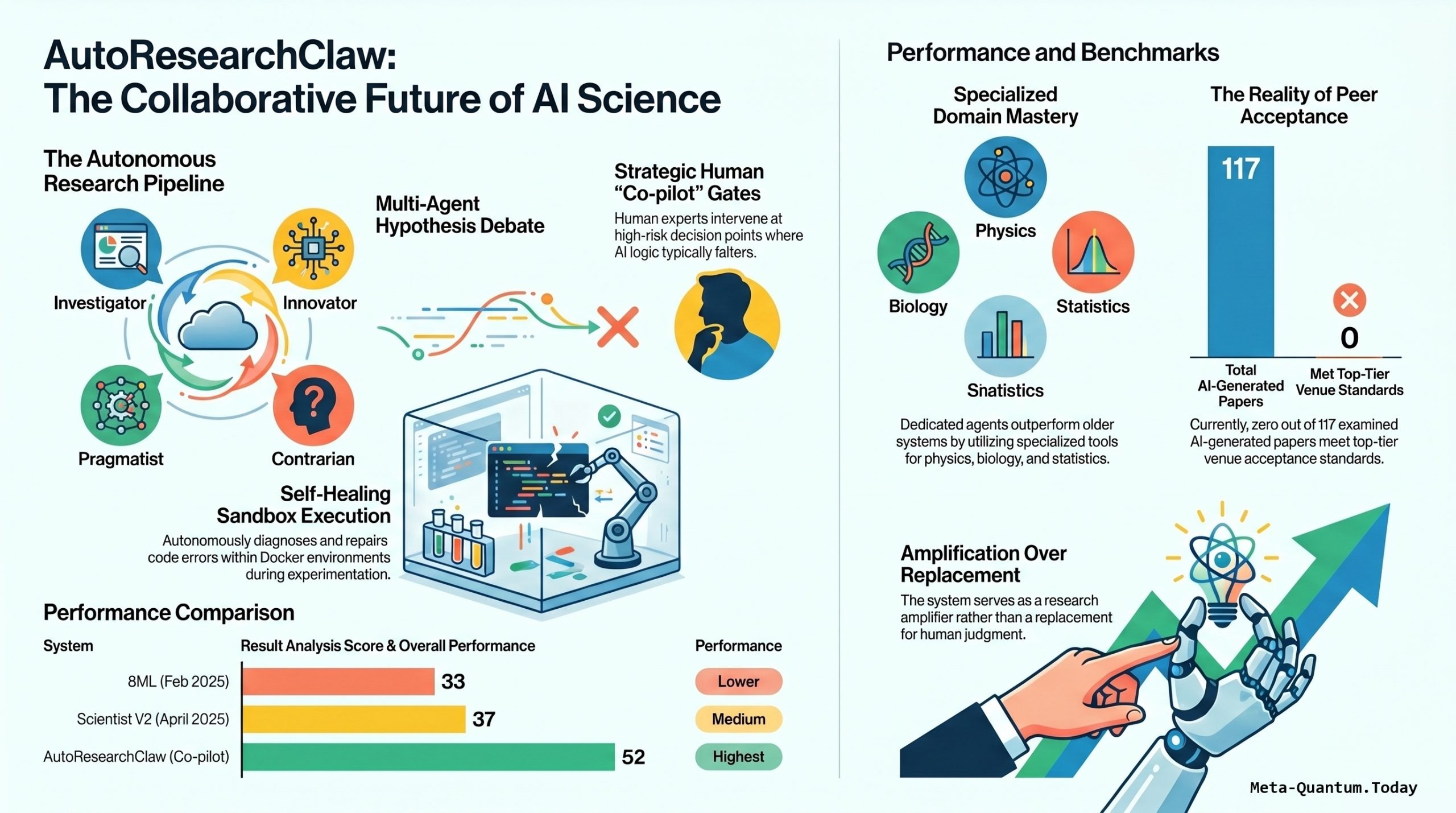
The video is sharpest in critiquing the evaluation. The authors define a feature-comparison table where AutoResearchClaw conveniently earns all green checkmarks (self-healing, citation verification, human-in-the-loop gating) — features the competing systems were never built around. They also introduce their own ARC benchmark: a 25-topic machine-learning suite (tabular ML, dimensionality reduction, NLP, AutoML, GP kernels, topic modeling, feature selection, causal discovery) plus a 20-topic scientific domain split (10 high-energy physics, 7 systems biology, 3 statistics).
Comparisons run against two systems that, in AI time, are ancient: an AI-driven code-exploration system (AIDE) from February 2025 and Sakana AI’s “The AI Scientist v2” from April 2025 — both over a year old. All systems use the same GPT-5.3 Codex backbone. Two terms matter:
- Co-pilot = a human intervenes at critical or high-risk decision points.
- Full auto = zero human interaction.
The results are tellingly modest. Code development scores are nearly identical across systems (~0.93–0.96). Code execution improves with multi-agents. The interesting metric is result analysis — whether the AI can judge if its own output makes sense. Full-auto AutoResearchClaw reaches only 0.44 (vs. the older AIDE’s 0.33), and only the team + human co-pilot configuration breaks above 0.5, at 0.52. For the domain-specialized tasks, AutoResearchClaw’s agents are equipped with field-specific skills (Feynman rules, MadGraph, and a collider-agent architecture for high-energy physics; flux-balance analysis for biology; Monte Carlo and semi-parametric inference for statistics) and run inside Claude Code rather than Codex. Unsurprisingly, the only system with these skills wins (e.g., 48% in high-energy physics while others fail) — which the narrator flags as a stacked comparison.
The Real Finding: Where Humans Matter
The case study (topic D10 — how cross-validation strategies differ for model selection on small datasets) crystallizes the lesson: full auto completely fails, but co-pilot succeeds. The reason isn’t that humans solve it directly — it’s that human guidance targets the experimental bottleneck and shows a way out, whereas full auto has none.
The authors’ insights are genuinely useful:
- Verification is necessary but not sufficient. A full-auto run can pass a numeric gate while the “verified” value is zero — and zero might be a legitimate measurement or a silent failure of the whole system. The gate can’t tell which.
- Co-pilot improves quality not through more intervention but through correctly placed intervention — at the moments where the AI cracks. Micromanaging every step both bores the human and adds little value.
- The proposed division of labor: humans make the high-stakes judgment calls (hypothesis co-creation, experiment-design review, shaping conclusions, scientific-faithfulness checks), while the AI handles low-risk execution — setup, Python, coding.
This human-at-the-gates pattern mirrors a broader trend in research-automation work, where decision gates are deliberately embedded at key stages so researchers can steer rather than rubber-stamp the pipeline.
Conclusion and Key Takeaways
The video’s punchline is the authors’ own closing statement: AutoResearchClaw is positioned as a research amplifier that accelerates exploration while keeping verifiability central — explicitly not a replacement for human scientific judgment. The 2024 prophecy of AI ousting the principal investigator has, by mid-2026, quietly collapsed into “AI helps you code and visualize faster.”
Key points:
- AutoResearchClaw v5 = a five-mechanism multi-agent pipeline (debate, self-healing execution, verifiable reporting, human-in-the-loop, mistake-to-safeguard memory).
- Headline gains are real but incremental; the standout improvement is result interpretation, and even that only clears 0.5 with a human co-pilot.
- Verification gates can be fooled by valid-looking-but-meaningless outputs (e.g., zeros) — automation alone can’t catch this.
- The winning recipe is strategic human input at the right decision points, not full autonomy and not micromanagement.
- Bonus paper (Cornell, May 18, 2026): “How far are we from true auto research with AI?” reached a parallel conclusion — none of the 117 AI-generated papers examined cleared the acceptance bar of a top-tier venue, suggesting we remain meaningfully short of true autonomous research.
- Net message: treat “AI will cure cancer” marketing with healthy skepticism; the current frontier is augmentation, not replacement.
Related References
- Official repo — aiming-lab/AutoResearchClaw (README,
config.researchclaw.example.yaml,docs/integration-guide.md, Tester Guide) - Paper — AutoResearchClaw: Self-Reinforcing Autonomous Research with Human-AI Collaboration (papers.cool/arxiv/2605.20025)
- MetaClaw (cross-run learning) · OpenClaw (chat-driven runner) · researchclaw-skill (setup wrapper)
- Lineage it credits: Sakana AI’s AI-Scientist, Karpathy’s AutoResearch, Analemma’s FARS
- AutoResearch Claw v5 paper — “Self-Reinforced Autonomous Research with Human–AI Collaboration” (published May 19, 2026; multi-institution: UNC Chapel Hill, UC Santa Cruz, CMU, NUS, UC Berkeley, Rutgers, NEC Labs America, Meta, Stanford, Google, University of Washington) + the open-source GitHub repository (MIT license).
- Cornell bonus paper — “How far are we from true auto research with AI?” (May 18, 2026), introducing SAR (agentic reviewer with human inspection) and PR (artifacts-aware peer review).
- Sakana AI — “The AI Scientist v2” (April 2025), one of the baseline comparison systems. (Sakana AI Scientist on arXiv/GitHub)
- AIDE — AI-Driven Exploration in the Space of Code (February 2025), the second baseline system.
- Related Glasp reading: The Complete Beginners Guide to Autonomous Agents and From AGI to Superintelligence: The Intelligence Explosion (highlights).
