

Introduction
A large-scale benchmark study published on May 13, 2026 by a consortium including Yale, Columbia, NVIDIA, NYU, Stevens Institute, Université de Montréal, Mila – Quebec AI Institute, Vrije Universiteit Amsterdam, NUS Singapore, and several other institutions. Powered by an NVIDIA academic grant of 32,000 A100 GPU hours, the study asks a deceptively simple question: when you pair a frontier LLM with an agent framework, which combination actually performs best on real financial intelligence tasks?
Four models (Claude Sonnet 4.6, GPT-5.4, Qwen 3.5 ~400B open-source, and Qwen 3.5 27B) were combined with five agent frameworks (ReAct, Claude Code, Codex, Hermes, OpenClaw) — yielding 20 configurations per workflow. The video’s narrator frames this as a control experiment to isolate the agentic framework variable from the LLM backbone variable, something the field has long needed.
Features and Concept
The study evaluates each configuration across four financial workflows that map onto increasingly difficult agentic skills:
- Trading — daily market timing for a single asset (buy/sell/hold), 3-month horizon with daily increments.
- Hedging — market-neutral pairs trading (long/short, short/long, hold, close), 3-month horizon. This tests cross-asset relational reasoning — analogous to exploiting local divergences in coupled oscillators.
- Market Insights — weekly investment reports with structured 8-section ratings to industry standard.
- Auditing — exact arithmetic and graph traversal logic across knowledge graphs and SEC filings.
Evaluation metrics include cumulative return, Sharpe ratio, maximum drawdown, and structural error rates. The conceptual framing borrows from theoretical physics: professional finance is treated as a non-equilibrium dynamical system driven by stochastic processes, requiring agents to integrate trajectories over long horizons, make sequential irreversible commitments under uncertainty, and preserve “topological invariants” (i.e., accounting identities).
Key Findings by Framework × Model
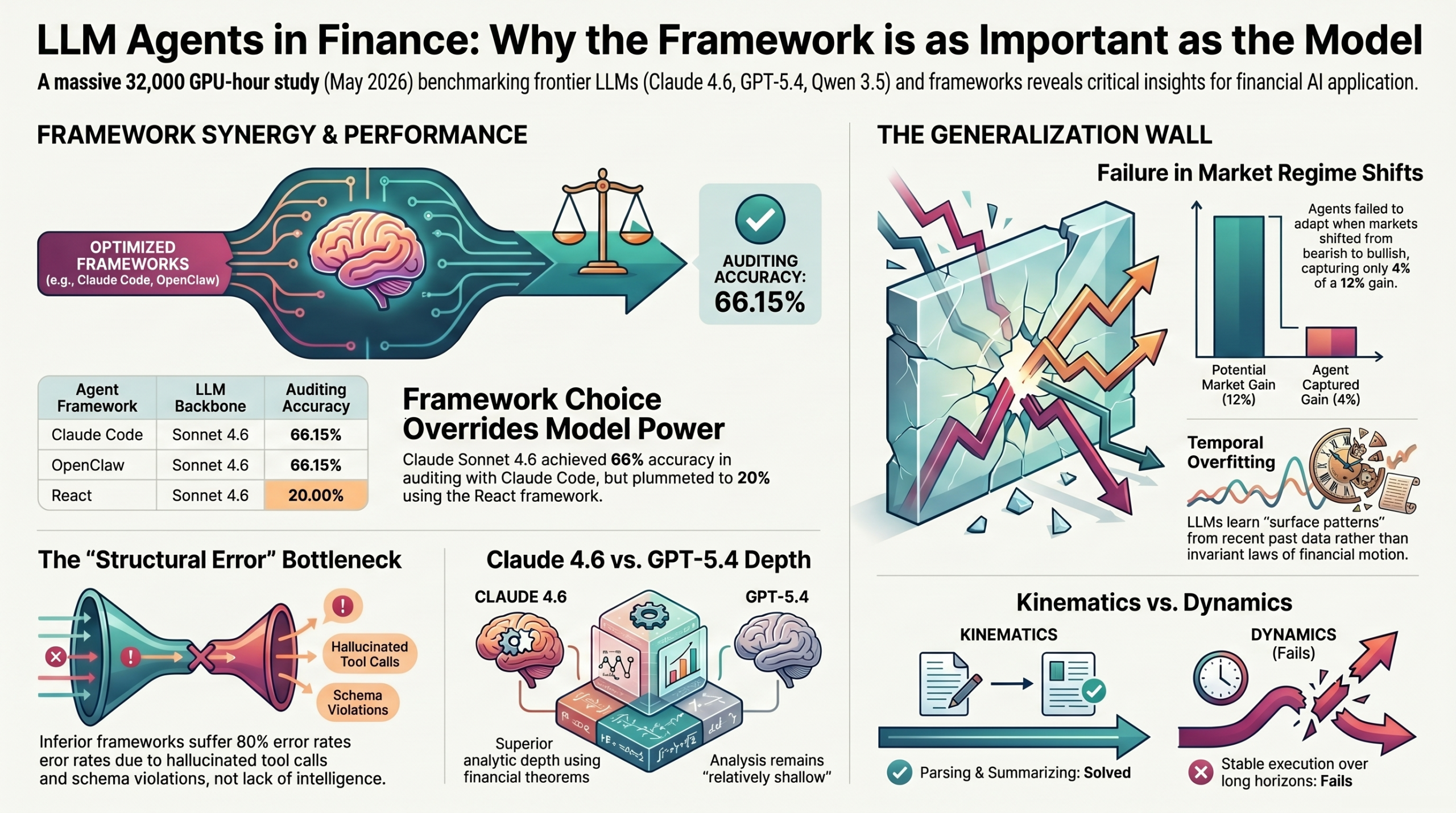
Auditing: Where the Framework Matters Most
The most striking result. With the same Claude Sonnet 4.6 backbone:
- Claude Code + Sonnet 4.6 → 66.15% accuracy
- OpenClaw + Sonnet 4.6 → 66.15% accuracy
- ReAct + Sonnet 4.6 → only 20% accuracy (80% structural error rate from hallucinated tool calls and schema violations)
- Hermes + Sonnet 4.6 → also ~20%
This is a clean demonstration that the integrator matters as much as the Hamiltonian — the agentic framework can swing accuracy by 3× with an identical LLM underneath.
Trading: Surprising Open-Source Wins
- Claude Code + Qwen 3.5 400B generated remarkable returns (profitable shorting / volatility-harvesting policy on MSFT).
- OpenClaw + Sonnet 4.6 also delivered strong alpha.
- Codex + Qwen 3.5 27B failed to even complete runs — the planner and tool-orchestration policy of Codex acts as an unstable integrator for that model.
The narrator interprets this as Codex vs. Claude Code being primarily a difference in planner and tool-orchestration policy, not surface capability — making this a control test of planning style.
Hedging: Open-Source Standouts in Hermes
The hedging chart yielded the most unexpected result: Hermes + Qwen 3.5 400B outperformed every proprietary configuration, with Claude Sonnet 4.6 placed second. GPT-5.4 underperformed in this framework. This raises the question of whether open-source backbones may have an unappreciated edge in certain agent architectures for relational reasoning tasks.
Live Out-of-Distribution Test (April–May 2026): The Collapse
The truly important section. After in-sample evaluation, the team ran a live forward test on unseen April–May 2026 data. Microsoft flipped from a bearish to a strongly bullish regime, and the previously winning Claude Code + Qwen 400B configuration captured only ~4% of the buy-and-hold baseline — a catastrophic failure to adapt.
The interpretation: current agents exhibit temporal overfitting. They learn local linear approximations of recent training data rather than the underlying invariant laws of market dynamics. The moment the stochastic drift enters a new regime, policy functions break down.
Related Sections and Broader Themes
Generation ≠ Verification
Market Insights (a generative task on latent statistical mapping) approached a performance ceiling. But the same agents failed on hedging (persistent state memory across assets) and auditing (exact arithmetic and graph traversal). Strong performance in one financial task does not predict strong performance in another.
Brittle Generalization Over Long Horizons
“Long horizon” here means 6+ reasoning steps. Even Sonnet 4.6 and GPT-5.4 struggle to generate stable alpha across different assets — an agent might beat the buy-and-hold baseline on Microsoft but catastrophically fail on Tesla. The learned representations are not invariant across volatility regimes, meaning what looks like reasoning is closer to pattern matching. This echoes a broader concern in the literature that scaling backbone parameters alone is insufficient for genuine reasoning generalization — a theme also raised in work showing that emergent abilities in LLMs may depend heavily on chosen evaluation metrics rather than reflecting deep capability shifts (Glasp: Evolution of Emergent Abilities in LLMs).
Why Frameworks Differ
Claude Code operates as an autonomous loop with native file editing and batch execution, which successfully bounds Qwen 400B’s multi-trajectory exploration and preserves alpha across long horizons. ReAct, by contrast, suffers rapid trajectory collapse on the same backbone. This connects to a long-standing observation that LLMs alone struggle with long-horizon planning, and that pairing them with proper planning/orchestration scaffolds (e.g., LLM+P-style architectures combining LLMs with classical planners) is what unlocks reliable execution (Glasp: LLM+P – Empowering LLMs with Optimal Planning Proficiency).
Reasoning Depth Differentiator
On reasoning quality specifically, the authors note Claude Sonnet 4.6 demonstrates superior analytical depth, explicitly leveraging domain knowledge and applying financial theorems, whereas GPT-5.4’s analysis remains relatively shallow — a distinct capability gap in complex analytical synthesis.
The Path Forward: External Harness Over Tensor Retraining
A key insight teased at the end: the control loop can be externalized to an AI harness rather than baked into the LLM tensor weights. This is consistent with the broader move toward multi-agent and modular architectures where specialized components collaborate rather than relying on one monolithic backbone (Glasp: Harnessing the Power of Multi-Stage Language Model Programs). The narrator points toward an upcoming Princeton/Google solution involving a continual harness with dynamic memory and skill integration.
YouTube : Unlocking Agentic Alpha: 4 LLMS in Codex, Claude Code, Hermes, OpenClaw on Financial Markets
Conclusion and Key Takeaways
The video delivers a sober but clarifying picture. AI has solved the kinematics of financial reasoning — parsing filings, summarizing, fluent analytical output. It has not solved the dynamics — stable multi-step execution policies under temporal flux.
Key takeaways:
- Framework choice can swing accuracy by 3× on the same LLM backbone. ReAct is now structurally inferior to CLI-oriented frameworks (Claude Code, OpenClaw) for tasks requiring tool fidelity.
- Claude Code and OpenClaw consistently top the charts for Sonnet 4.6 across auditing and trading.
- Hermes paired with Qwen 3.5 400B is a sleeper combination worth watching — an open-source stack beating proprietary alternatives in hedging.
- Codex + Qwen models is an unstable pairing — the planner mismatch produces divergent trajectories.
- Temporal overfitting is real and severe — in live April–May 2026 data, even the winning configurations captured only ~4% of buy-and-hold returns when regime shifted.
- Frontier scaling is no longer enough — the next frontier is the geometry of the adjugate control loop, likely solved via external harnesses rather than bigger weights.
- Reasoning depth still favors Claude Sonnet 4.6 over GPT-5.4 for complex financial analytical synthesis.
- Apply with caution: no current LLM+agent configuration is safe for real-money financial prediction.
Related References
- Study (May 13, 2026): Yale, Columbia, NVIDIA, NYU, Stevens, Université de Montréal, Mila Quebec, VU Amsterdam, NUS Singapore, et al. — agentic benchmark for financial intelligence
- NVIDIA Academic Grant Program (32,000 A100 GPU hours)
- Related work on information leakage in LLM-based financial agents: Profit Mirage: Revisiting Information Leakage in LLM-based Financial Agents (arXiv 2510.07920)
- TimeSeek: Temporal Reliability of Agentic Forecasters (arXiv 2604.04220) — complementary work on time-aware evaluation
- TrustTrade: Human-Inspired Selective Consensus Reduces Decision Uncertainty in LLM Trading Agents — on stabilizing LLM trading behavior
- Glasp insight: LLM+P – Empowering LLMs with Optimal Planning Proficiency
- Glasp insight: Harnessing the Power of Multi-Stage Language Model Programs
- Glasp insight: The Evolution of Emergent Abilities in Large Language Models
