

引言
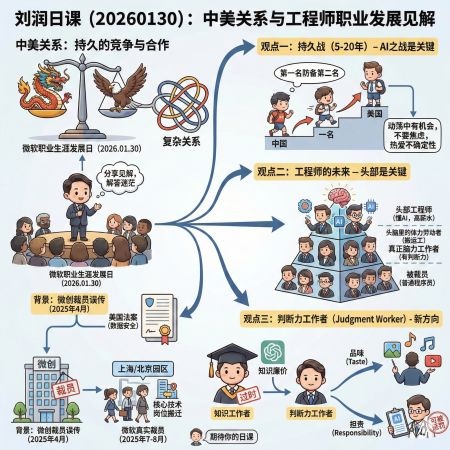
2026年1月30日,刘润应邀回到微软上海园区,参加微软的Career Day(职业生涯发展日)活动。面对线上线下众多微软同仁,他分享了对当前中美关系、AI时代变革以及工程师职业发展的深刻见解。这次分享的背景是微软中国经历了一系列因中美关系紧张而导致的业务调整和人员变动,许多员工对未来感到迷茫。刘润通过三个核心观点,为大家提供了一个清晰的思考框架。内容包含人工智能软件工程师之路。
关于微软职业生涯发展mp3音频:
1. 中美关系:这是一场持久战(5-20年)
1.1 微软中国的现实困境
2025年4月,微软的合作伙伴微创公司(微软与上海市政府的合资公司)因美国针对”敌对国家”(adversary country)的法案,失去了约2000人的客户服务外包合约。这些员工原本在中国服务美国、印度等其他国家的客户,但新法案禁止”敌对国家”接触美国用户数据。
到7-8月,微软上海和北京园区也真正开始裁员,原因是中国员工不能再接触某些美国核心技术,员工要么搬到加拿大、美国,要么被解约。
1.2 AI之战:人类的最后一场战争
刘润指出,这不是一两年就能结束的问题,而是一场可能持续5-20年的长期对抗。核心原因是:
- AI是人类最后一个发明:一旦AI被发明出来,所有其他发明都将由AI完成
- 领先半个身位就能永远领先:谁先掌握AI技术,就能在后续所有领域保持优势
- 从倒数第一到第二名的竞争:当中国从”班级最后一名”爬升到”第二名”,要与”第一名”美国竞争全国冠军时,合作关系就变成了竞争关系
1.3 不确定性中蕴藏机会
刘润强调,这个世界只要不变化,就永远是在位者的天下。正是因为有了巨大变化和动荡,才会产生新的机会。这恰恰是这一代年轻人的机遇——那些热爱不确定性的人才能获得成功。
2. 工程师的未来:关键在于是否处于头部
2.1 裁掉的和留下的都是程序员
面对大量工程师裁员的现实,刘润提出了一个反直觉的观点:
- 被裁掉的是程序员,留下来的还是程序员
- 现在懂AI的程序员薪资比以前高得多,”一将难求”
- 区别不在于你是不是程序员,而在于你是不是在头部
2.2 头脑里的体力劳动者 vs 真正的脑力劳动者
刘润创造了一个新概念:”头脑里的体力劳动者”:
- 头脑体力劳动:把Excel内容搬到PPT里,把知识库内容用电话说给别人听
- 真正脑力劳动:掌握底层技术,具有真正的判断力
要成为工程师头部,必须懂最底层的技术,而不仅仅是做简单的信息搬运工作。
3. 从知识工作者到判断力工作者
3.1 知识已经廉价化
彼得·德鲁克提出的”知识工作者”(Knowledge Worker)概念可能已经过时:
- AI能读的书比人一辈子读的都多
- AI掌握的知识比人十辈子掌握的都多
- 知识已经变得唾手可得、非常廉价
- “知识改变命运”这句话已经不再成立
3.2 判断力工作者(Judgment Worker)
刘润提出了新概念:”判断力工作者”,其核心能力体现在两个方向:
品味(Taste)
- AI可以画图、做音乐、做视频,但能否发出去需要人来判断
- 判断作品是否足够好听、好看,需要人的品味
- 品味这个东西最终是由人来决定的
担责(Responsibility)
- 医生不敢直接让患者按AI的诊断吃药,因为需要有人承担责任
- AI无法被惩罚,但人可以被惩罚
- 正因为可以被惩罚,所以才能担责
- 为了不被惩罚,人必须运用自己的判断
未来不是知识改变命运,而是判断力改变命运。
人工智能软件工程师之路:从入门到精通的完整指南
AI发展对软件工程师的影响与未来发展方向
AI对软件工程师的深刻影响
1. 生产力的指数级提升
编程效率革命
- GitHub Copilot、Cursor、Claude Code等AI编程助手使编码速度提升3-10倍
- 从”写代码”转向”审查和优化代码”
- 一个优秀工程师配合AI,可以完成过去5-10人团队的工作量
岗位分化加剧
- 头部20%工程师:薪资暴涨,需求旺盛
- 中间60%工程师:面临被AI替代的压力
- 底部20%工程师:快速被淘汰
2. 工作内容的根本性转变
从编码者到架构者
过去:写代码 → 测试 → 部署
现在:设计架构 → AI生成代码 → 审查优化 → 系统集成
被AI替代的工作
- 重复性代码编写(CRUD操作、API封装)
- 简单的bug修复
- 标准化的测试用例编写
- 基础文档编写
- 代码格式化和重构
难以被替代的工作
- 复杂系统架构设计
- 技术方案决策
- 跨系统集成
- 性能优化和问题诊断
- 业务理解和需求转化
AI时代的新物种
在刘润的微软分享中有一句话:”现在懂AI的程序员比原来有高得多的薪水,现在一将难求啊。”这不是夸张,而是现实。AI软件工程师正在成为科技行业最炙手可热的岗位,也是未来十年最具发展潜力的职业方向。
什么是AI软件工程师?
AI软件工程师不是单纯的机器学习研究员,也不是传统的软件开发工程师,而是两者的融合体:
AI软件工程师 = 软件工程能力 × AI技术理解 × 工程化落地能力
他们能够:
- 将AI模型转化为可部署的生产系统
- 设计和构建AI驱动的应用架构
- 优化AI系统的性能、成本和可靠性
- 解决AI落地过程中的工程问题
第1部分:为什么要成为AI软件工程师?
1.1 市场需求激增
薪资数据(2025-2026)
传统软件工程师: $80K - $150K
AI软件工程师: $120K - $300K
AI架构师: $200K - $500K
岗位需求
- OpenAI、Anthropic等AI公司:年薪$300K+起步
- 传统科技公司AI团队:薪资溢价50%-100%
- 创业公司AI岗位:股权+高薪
1.2 技术趋势不可逆
AI渗透各行各业
医疗:AI诊断、药物研发
金融:风控、量化交易
教育:个性化学习、AI导师
制造:智能质检、供应链优化
娱乐:内容生成、游戏AI
每个行业都需要AI软件工程师来落地这些应用。
1.3 职业安全性更高
反直觉的事实:
- AI替代的是”不懂AI的程序员”
- 懂AI的工程师需求量暴增
- AI工程师是AI革命的建设者,而非受害者
第2部分:AI软件工程师技能树
2.1 基础层:必备的软件工程能力
编程语言(按优先级)
# 1. Python(必须精通)
# - AI/ML生态的核心语言
# - 90%的AI项目使用Python
# 基础要求
- 数据结构和算法
- 面向对象编程
- 函数式编程
- 异步编程
# 核心库
import numpy as np # 数值计算
import pandas as pd # 数据处理
import matplotlib as plt # 可视化
// 2. JavaScript/TypeScript(前端AI应用)
// - Web AI应用开发
// - 浏览器端AI推理
// 3. Go/Rust(高性能AI服务)
// - AI服务后端
// - 模型推理引擎
软件工程基础
# 版本控制
git, GitHub/GitLab
# 容器化
Docker, Kubernetes
# CI/CD
GitHub Actions, Jenkins
# 数据库
PostgreSQL, MongoDB, Redis
# 消息队列
RabbitMQ, Kafka
# API设计
RESTful, GraphQL, gRPC
2.2 AI核心层:机器学习与深度学习
理论基础(必须理解)
1. 机器学习基础
# 监督学习
- 线性回归、逻辑回归
- 决策树、随机森林
- SVM、KNN
# 非监督学习
- K-means聚类
- PCA降维
- 异常检测
# 评估指标
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
2. 深度学习核心
# 神经网络基础
- 前向传播、反向传播
- 激活函数、损失函数
- 优化算法(SGD, Adam等)
# 核心架构
import torch
import torch.nn as nn
class SimpleNN(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(784, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = torch.relu(self.fc1(x))
return self.fc2(x)
# CNN(计算机视觉)
- 卷积层、池化层
- ResNet, EfficientNet
# RNN/LSTM(序列数据)
- 循环神经网络
- 长短期记忆网络
# Transformer(核心中的核心)
- 注意力机制
- BERT, GPT架构
3. 大模型时代核心概念
# LLM基础
- Transformer架构深入理解
- Tokenization
- Embedding和位置编码
- 注意力机制(Self-Attention, Multi-Head Attention)
# 训练技术
- Pre-training, Fine-tuning
- RLHF(人类反馈强化学习)
- LoRA, QLoRA(低秩适配)
- Prompt Engineering
# 推理优化
- 量化(INT8, INT4)
- KV Cache
- Flash Attention
- Speculative Decoding
实践框架(必须会用)
深度学习框架
# PyTorch(首选)
import torch
from torch.utils.data import DataLoader
from transformers import AutoModel, AutoTokenizer
# 加载预训练模型
model = AutoModel.from_pretrained("bert-base-uncased")
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# TensorFlow/Keras(备选)
import tensorflow as tf
LLM应用框架
# LangChain(AI应用开发)
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
# LlamaIndex(RAG应用)
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# HuggingFace Transformers(模型库)
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
2.3 AI工程化层:从模型到产品
模型部署
# 模型服务化
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class PredictionRequest(BaseModel):
text: str
@app.post("/predict")
async def predict(request: PredictionRequest):
# 模型推理逻辑
result = model.predict(request.text)
return {"prediction": result}
# 容器化部署
# Dockerfile
FROM python:3.10-slim
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY . .
CMD ["uvicorn", "main:app", "--host", "0.0.0.0"]
模型优化
# 量化
import torch.quantization as quantization
model_int8 = quantization.quantize_dynamic(
model, {nn.Linear}, dtype=torch.qint8
)
# 模型剪枝
import torch.nn.utils.prune as prune
prune.l1_unstructured(model.layer, name="weight", amount=0.3)
# 蒸馏
# 将大模型知识转移到小模型
MLOps
# 完整的AI工程流程
数据收集 → 数据清洗 → 特征工程 → 模型训练 →
模型评估 → 模型部署 → 监控与维护
# 工具链
- 数据版本控制:DVC
- 实验跟踪:MLflow, Weights & Biases
- 模型注册:MLflow Model Registry
- 自动化训练:Kubeflow, Airflow
- 监控:Prometheus, Grafana
2.4 应用层:AI产品开发
RAG(检索增强生成)
# 完整的RAG系统
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
# 1. 文档加载和分割
documents = SimpleDirectoryReader('data').load_data()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
texts = text_splitter.split_documents(documents)
# 2. 创建向量数据库
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(texts, embeddings)
# 3. 创建QA链
qa_chain = RetrievalQA.from_chain_type(
llm=OpenAI(),
retriever=vectorstore.as_retriever()
)
# 4. 查询
response = qa_chain.run("你的问题")
AI Agent开发
# 自主AI代理
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
tools = [
Tool(
name="Search",
func=search_tool,
description="搜索互联网信息"
),
Tool(
name="Calculator",
func=calculator_tool,
description="执行数学计算"
),
]
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
agent.run("帮我找到今天的天气并计算温度的平均值")
多模态应用
# 图像理解
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# 图像分类
inputs = processor(text=["猫", "狗"], images=image, return_tensors="pt")
outputs = model(**inputs)
# 文生图
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("stable-diffusion-v1-5")
image = pipe("一只可爱的猫咪").images[0]
第3部分:学习路径(0到1的完整计划)
阶段一:基础准备(1-3个月)
目标:建立坚实的编程和数学基础
第1-2周:Python基础强化
# 学习资源
- 《Python Crash Course》
- LeetCode刷题(简单-中等难度50题)
# 实践项目
def fibonacci(n):
"""斐波那契数列 - 递归与动态规划"""
if n <= 1:
return n
dp = [0] * (n + 1)
dp[1] = 1
for i in range(2, n + 1):
dp[i] = dp[i-1] + dp[i-2]
return dp[n]
# 必做项目
1. 构建一个命令行TODO应用
2. 实现一个简单的web爬虫
3. 数据分析:分析一个CSV数据集
第3-4周:数学基础
# 线性代数
import numpy as np
# 矩阵运算
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
C = np.dot(A, B) # 矩阵乘法
# 特征值和特征向量
eigenvalues, eigenvectors = np.linalg.eig(A)
# 概率统计
import scipy.stats as stats
# 正态分布
data = stats.norm.rvs(loc=0, scale=1, size=1000)
# 微积分(了解梯度下降原理)
def gradient_descent(f, df, x0, learning_rate=0.01, iterations=100):
x = x0
for i in range(iterations):
x = x - learning_rate * df(x)
return x
学习资源:
- 线性代数:3Blue1Brown的《线性代数的本质》
- 概率统计:Khan Academy
- 微积分:MIT 18.01
第5-12周:机器学习基础
教材:
- 吴恩达《Machine Learning》课程(Coursera)
- 《Hands-On Machine Learning》
实践项目:
# 项目1:房价预测(线性回归)
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)
model = LinearRegression()
model.fit(X_train, y_train)
predictions = model.predict(X_test)
# 项目2:垃圾邮件分类(朴素贝叶斯)
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
X_train_vec = vectorizer.fit_transform(X_train)
model = MultinomialNB()
model.fit(X_train_vec, y_train)
# 项目3:图像分类(随机森林)
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train, y_train)
阶段二:深度学习与大模型(3-6个月)
第13-16周:深度学习基础
教材:
- 吴恩达《Deep Learning Specialization》
- 《Deep Learning》(花书)
实践项目:
# 项目1:手写数字识别(MNIST)
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3)
self.conv2 = nn.Conv2d(32, 64, 3)
self.fc1 = nn.Linear(64 * 5 * 5, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = torch.relu(self.conv1(x))
x = torch.max_pool2d(x, 2)
x = torch.relu(self.conv2(x))
x = torch.max_pool2d(x, 2)
x = x.view(-1, 64 * 5 * 5)
x = torch.relu(self.fc1(x))
return self.fc2(x)
# 训练循环
model = Net()
optimizer = optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()
for epoch in range(10):
for data, target in train_loader:
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 项目2:图像分类(CIFAR-10,使用预训练模型)
from torchvision.models import resnet18
model = resnet18(pretrained=True)
model.fc = nn.Linear(512, 10) # 修改最后一层
第17-20周:Transformer与大模型
核心学习:
# 1. 从零实现简单Transformer
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
batch_size = q.size(0)
# Linear projections
q = self.W_q(q).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
k = self.W_k(k).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
v = self.W_v(v).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# Attention
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attention = F.softmax(scores, dim=-1)
context = torch.matmul(attention, v)
# Concatenate heads
context = context.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
return self.W_o(context)
# 2. 使用HuggingFace Transformers
from transformers import BertForSequenceClassification, BertTokenizer
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 微调BERT
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=16,
warmup_steps=500,
weight_decay=0.01,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset
)
trainer.train()
实践项目:
- 情感分析系统(微调BERT)
- 文本摘要(使用T5/BART)
- 问答系统(使用RoBERTa)
第21-24周:LLM应用开发
核心技能:
# 1. Prompt Engineering
from langchain.prompts import PromptTemplate
template = """
你是一个专业的{role}。
根据以下信息回答问题:
背景信息:{context}
问题:{question}
请提供详细且准确的回答。
"""
prompt = PromptTemplate(
template=template,
input_variables=["role", "context", "question"]
)
# 2. RAG系统构建
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
# 加载文档
loader = TextLoader('data.txt')
documents = loader.load()
# 分割文档
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
# 创建向量存储
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(docs, embeddings)
# 检索
retriever = db.as_retriever()
results = retriever.get_relevant_documents("你的查询")
# 3. Function Calling
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定城市的天气",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string"},
},
"required": ["city"]
}
}
}
]
实战项目:
- 智能客服系统(RAG + Function Calling)
- 代码助手(Code Copilot)
- 文档分析工具
阶段三:AI工程化(6-9个月)
第25-28周:模型部署与优化
实践项目:
# 1. 模型服务化
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import torch
app = FastAPI()
class InferenceRequest(BaseModel):
text: str
max_length: int = 100
class InferenceResponse(BaseModel):
generated_text: str
confidence: float
@app.post("/generate", response_model=InferenceResponse)
async def generate(request: InferenceRequest):
try:
# 模型推理
inputs = tokenizer(request.text, return_tensors="pt")
outputs = model.generate(**inputs, max_length=request.max_length)
generated_text = tokenizer.decode(outputs[0])
return InferenceResponse(
generated_text=generated_text,
confidence=0.95
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
# 2. 模型量化
import torch.quantization
# 动态量化
quantized_model = torch.quantization.quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.qint8
)
# 静态量化
model.qconfig = torch.quantization.get_default_qconfig('fbgemm')
torch.quantization.prepare(model, inplace=True)
# 校准
torch.quantization.convert(model, inplace=True)
# 3. ONNX导出
torch.onnx.export(
model,
dummy_input,
"model.onnx",
export_params=True,
opset_version=11,
do_constant_folding=True
)
# 4. TensorRT优化
import tensorrt as trt
# 构建TensorRT引擎
builder = trt.Builder(TRT_LOGGER)
network = builder.create_network()
parser = trt.OnnxParser(network, TRT_LOGGER)
第29-32周:MLOps实践
完整的MLOps流程:
# 1. 实验跟踪(MLflow)
import mlflow
with mlflow.start_run():
mlflow.log_param("learning_rate", 0.01)
mlflow.log_param("batch_size", 32)
# 训练模型
for epoch in range(num_epochs):
loss = train_epoch(model, train_loader)
mlflow.log_metric("loss", loss, step=epoch)
# 保存模型
mlflow.pytorch.log_model(model, "model")
# 2. 数据版本控制(DVC)
# dvc.yaml
stages:
prepare:
cmd: python prepare_data.py
deps:
- raw_data/
outs:
- processed_data/
train:
cmd: python train.py
deps:
- processed_data/
- train.py
outs:
- models/model.pkl
metrics:
- metrics.json
# 3. 自动化pipeline(Airflow)
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
dag = DAG('ml_pipeline', schedule_interval='@daily')
prepare_task = PythonOperator(
task_id='prepare_data',
python_callable=prepare_data,
dag=dag
)
train_task = PythonOperator(
task_id='train_model',
python_callable=train_model,
dag=dag
)
deploy_task = PythonOperator(
task_id='deploy_model',
python_callable=deploy_model,
dag=dag
)
prepare_task >> train_task >> deploy_task
# 4. 监控(Prometheus + Grafana)
from prometheus_client import Counter, Histogram, start_http_server
# 定义指标
inference_counter = Counter('model_inference_total', 'Total inference requests')
inference_duration = Histogram('model_inference_duration_seconds', 'Inference duration')
@inference_duration.time()
def predict(data):
inference_counter.inc()
return model.predict(data)
第33-36周:高级主题
1. 分布式训练
# PyTorch DDP
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
def setup(rank, world_size):
dist.init_process_group("nccl", rank=rank, world_size=world_size)
def train(rank, world_size):
setup(rank, world_size)
model = YourModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
for epoch in range(num_epochs):
for data, labels in train_loader:
outputs = ddp_model(data)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# DeepSpeed
import deepspeed
model_engine, optimizer, _, _ = deepspeed.initialize(
model=model,
model_parameters=model.parameters(),
config_params=ds_config
)
for step, batch in enumerate(data_loader):
loss = model_engine(batch)
model_engine.backward(loss)
model_engine.step()
2. 模型微调技术
# LoRA
from peft import get_peft_model, LoraConfig, TaskType
config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=8,
lora_alpha=32,
lora_dropout=0.1
)
model = get_peft_model(base_model, config)
# QLoRA(4bit量化 + LoRA)
from transformers import BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config
)
3. 自定义AI Agent
# LangGraph - 构建复杂的AI工作流
from langgraph.graph import Graph, StateGraph
class AgentState(TypedDict):
messages: List[BaseMessage]
next: str
def create_agent_graph():
workflow = StateGraph(AgentState)
# 定义节点
workflow.add_node("researcher", research_node)
workflow.add_node("writer", write_node)
workflow.add_node("reviewer", review_node)
# 定义边
workflow.add_edge("researcher", "writer")
workflow.add_edge("writer", "reviewer")
workflow.add_conditional_edges(
"reviewer",
should_continue,
{
"continue": "writer",
"end": END
}
)
workflow.set_entry_point("researcher")
return workflow.compile()
阶段四:实战项目(9-12个月)
项目1:企业级RAG系统
系统架构:
┌─────────────┐
│ 用户界面 │ (Streamlit/React)
└──────┬──────┘
│
┌──────▼─────────────────────────────┐
│ API Gateway (FastAPI) │
├───────────┬────────────┬───────────┤
│ 查询处理 │ 文档管理 │ 用户管理 │
└──────┬────┬────────────┴───────────┘
│ │
┌──────▼────▼────────┐ ┌──────────────┐
│ 向量数据库 │ │ LLM服务 │
│ (Pinecone/Weaviate)│ │ (OpenAI/本地)│
└────────────────────┘ └──────────────┘
核心代码:
from fastapi import FastAPI, UploadFile
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
from langchain.chains import ConversationalRetrievalChain
import pinecone
app = FastAPI()
# 初始化
pinecone.init(api_key=PINECONE_API_KEY)
embeddings = OpenAIEmbeddings()
vectorstore = Pinecone(index_name="documents", embedding=embeddings)
@app.post("/upload")
async def upload_document(file: UploadFile):
"""上传并处理文档"""
# 1. 读取文档
content = await file.read()
# 2. 分块
chunks = text_splitter.split_text(content)
# 3. 生成嵌入并存储
vectorstore.add_texts(chunks)
return {"status": "success", "chunks": len(chunks)}
@app.post("/query")
async def query(question: str, chat_history: List = []):
"""查询系统"""
# 创建对话链
qa_chain = ConversationalRetrievalChain.from_llm(
llm=ChatOpenAI(temperature=0),
retriever=vectorstore.as_retriever(),
return_source_documents=True
)
# 执行查询
result = qa_chain({"question": question, "chat_history": chat_history})
return {
"answer": result["answer"],
"sources": [doc.metadata for doc in result["source_documents"]]
}
项目2:AI代码助手
功能:
- 代码补全
- 代码解释
- Bug修复
- 代码重构
核心实现:
from transformers import AutoModelForCausalLM, AutoTokenizer
class CodeAssistant:
def __init__(self, model_name="codellama/CodeLlama-7b-hf"):
self.model = AutoModelForCausalLM.from_pretrained(model_name)
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
def complete_code(self, code_context, max_length=100):
"""代码补全"""
inputs = self.tokenizer(code_context, return_tensors="pt")
outputs = self.model.generate(
**inputs,
max_length=max_length,
temperature=0.2,
top_p=0.95
)
return self.tokenizer.decode(outputs[0])
def explain_code(self, code):
"""代码解释"""
prompt = f"""
请解释以下代码的功能:
```python
{code}
```
解释:
"""
return self.generate(prompt)
def fix_bug(self, code, error_message):
"""Bug修复"""
prompt = f"""
以下代码出现了错误:
代码:
```python
{code}
```
错误信息:
{error_message}
请提供修复后的代码:
"""
return self.generate(prompt)
项目3:多模态AI应用
功能:
- 图像理解和描述
- 视频分析
- 图像生成
- 图文互转
实现示例:
from transformers import BlipProcessor, BlipForConditionalGeneration
from diffusers import StableDiffusionPipeline
import torch
class MultimodalAI:
def __init__(self):
# 图像理解模型
self.blip_processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
self.blip_model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
# 图像生成模型
self.sd_pipe = StableDiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1",
torch_dtype=torch.float16
)
self.sd_pipe.to("cuda")
def image_to_text(self, image):
"""图像描述生成"""
inputs = self.blip_processor(image, return_tensors="pt")
outputs = self.blip_model.generate(**inputs)
caption = self.blip_processor.decode(outputs[0], skip_special_tokens=True)
return caption
def text_to_image(self, prompt, negative_prompt=""):
"""文本生成图像"""
image = self.sd_pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=50
).images[0]
return image
def visual_qa(self, image, question):
"""视觉问答"""
inputs = self.blip_processor(image, question, return_tensors="pt")
outputs = self.blip_model.generate(**inputs)
answer = self.blip_processor.decode(outputs[0], skip_special_tokens=True)
return answer
第4部分:职业发展路径
4.1 初级AI工程师(0-2年)
岗位职责:
- 使用现有AI框架开发应用
- 微调预训练模型
- 部署和维护AI模型
- 参与数据处理和特征工程
薪资范围: $80K – $120K
关键技能:
- Python编程
- PyTorch/TensorFlow基础
- LangChain/LlamaIndex应用开发
- 基础MLOps
4.2 中级AI工程师(2-4年)
岗位职责:
- 设计AI系统架构
- 优化模型性能
- 构建MLOps流程
- 技术方案选型
薪资范围: $120K – $180K
关键技能:
- 深度学习原理深入理解
- 大规模模型训练和优化
- 系统设计能力
- 跨团队协作
4.3 高级AI工程师/AI架构师(4-7年)
岗位职责:
- 主导复杂AI项目
- AI技术战略规划
- 团队技术领导
- 攻克技术难题
薪资范围: $180K – $300K
关键技能:
- AI前沿技术跟踪
- 大规模系统架构设计
- 技术领导力
- 业务理解能力
4.4 资深AI专家/技术总监(7年+)
岗位职责:
- 公司AI战略制定
- 前沿技术研究
- 技术团队建设
- 行业影响力
薪资范围: $300K – $500K+股权
关键技能:
- 深厚的AI理论功底
- 战略思维
- 技术管理能力
- 行业洞察
第5部分:实用建议与资源
5.1 学习资源清单
在线课程:
必修课程:
1. 吴恩达机器学习(Coursera) - 入门首选
2. 吴恩达深度学习专项课程 - 深度学习基础
3. Fast.ai Practical Deep Learning - 实践导向
4. Stanford CS224N - NLP专题
5. Stanford CS231N - 计算机视觉
进阶课程:
6. DeepLearning.AI LLM专项课程
7. Full Stack Deep Learning
8. MLOps Specialization
书籍推荐:
基础:
- 《Python Machine Learning》
- 《Hands-On Machine Learning》
- 《Deep Learning》(花书)
进阶:
- 《Designing Data-Intensive Applications》
- 《Building Machine Learning Powered Applications》
- 《Natural Language Processing with Transformers》
实践平台:
- Kaggle:数据科学竞赛
- GitHub:开源项目
- HuggingFace:模型和数据集
- Papers with Code:论文复现
5.2 如何保持竞争力
每日习惯(1小时):
def daily_routine():
# 早晨(30分钟)
read_ai_news() # Reddit r/MachineLearning, HackerNews
review_papers() # arXiv最新论文
# 晚上(30分钟)
code_practice() # LeetCode或小项目
document_learning() # 写技术博客
return "持续进步"
每周任务(5-10小时):
- 深入学习一个新技术点
- 完成一个小项目或Kaggle竞赛
- 阅读2-3篇重要论文
- 参与开源项目贡献
每月目标:
- 掌握一个新工具/框架
- 写一篇技术博客
- 参加技术meetup或会议
- 更新个人项目portfolio
5.3 构建个人品牌
GitHub策略:
# 1. 高质量开源项目
my-ai-toolkit/
├── rag-system/ # RAG系统实现
├── model-optimizer/ # 模型优化工具
├── ai-deployment/ # 部署最佳实践
└── learning-notes/ # 学习笔记和教程
# 2. 贡献开源项目
- LangChain, LlamaIndex
- HuggingFace Transformers
- PyTorch相关项目
# 3. 保持活跃
- 每周至少3次commit
- 回复issues和PR
- 写详细的README和文档
技术博客:
内容方向:
1. 技术教程(How-to)
2. 项目实战(Project)
3. 论文解读(Paper Review)
4. 工具对比(Tool Comparison)
5. 踩坑经验(Troubleshooting)
发布平台:
- 个人博客(建议使用Hugo/Jekyll)
- Medium
- Dev.to
- 知乎/掘金(中文)
社交媒体:
Twitter/X:
- 分享AI最新动态
- 参与技术讨论
- 关注AI领域KOL
LinkedIn:
- 展示项目成果
- 分享职业见解
- 建立专业网络
5.4 面试准备
技术面试常见问题:
# 1. 机器学习基础
"""
- 解释过拟合和欠拟合
- 偏差-方差权衡
- 各种优化算法的区别(SGD, Adam, RMSprop)
- 正则化技术(L1, L2, Dropout)
- 交叉验证方法
"""
# 2. 深度学习
"""
- 解释反向传播算法
- CNN的原理和应用
- RNN/LSTM的区别和应用
- Transformer架构详解
- 注意力机制原理
"""
# 3. 大模型
"""
- 预训练和微调的区别
- LoRA原理和优势
- RAG系统设计
- Prompt Engineering技巧
- 模型量化方法
"""
# 4. 系统设计
"""
问题:设计一个推荐系统
回答框架:
1. 明确需求(日活用户、推荐场景)
2. 系统架构(召回层、排序层、重排层)
3. 技术选型(模型、数据库、缓存)
4. 性能优化(延迟、吞吐量)
5. 监控和迭代
"""
# 5. 编程题
# 实现一个简单的神经网络
class NeuralNetwork:
def __init__(self, layers):
self.weights = []
self.biases = []
for i in range(len(layers) - 1):
w = np.random.randn(layers[i], layers[i+1]) * 0.01
b = np.zeros((1, layers[i+1]))
self.weights.append(w)
self.biases.append(b)
def forward(self, X):
self.activations = [X]
for w, b in zip(self.weights, self.biases):
X = np.dot(X, w) + b
X = self.relu(X)
self.activations.append(X)
return X
def relu(self, X):
return np.maximum(0, X)
行为面试准备:
STAR法则:
- Situation(情境)
- Task(任务)
- Action(行动)
- Result(结果)
常见问题:
1. 描述你最有挑战的AI项目
2. 如何处理模型性能不佳的情况
3. 团队协作经验
4. 技术决策过程
5. 失败经历和教训
第6部分:成功案例与启发
案例1:从传统开发到AI工程师
背景: 小李,传统Java后端开发,工作3年,薪资$90K
转型路径:
第1-3月:学习Python和机器学习基础
第4-6月:深入学习深度学习,完成Kaggle竞赛
第7-9月:开发个人AI项目(智能客服系统)
第10-12月:参与开源项目,建立个人品牌
结果:
- 转型成功,薪资$140K(+55%)
- GitHub 500+ stars
- 获得多个AI公司offer
关键成功因素:
- 每天学习2-3小时,坚持不懈
- 理论与实践结合
- 积极参与社区
- 建立可展示的项目portfolio
案例2:应届生的AI工程师之路
背景: 小王,计算机专业应届毕业生
准备过程:
大三下学期:
- 完成吴恩达机器学习课程
- 参加Kaggle竞赛,获得银牌
大四上学期:
- 深度学习专项课程
- 开发毕业设计(基于BERT的文本分类)
- 实习(AI创业公司)
大四下学期:
- 继续实习,参与真实项目
- 准备技术面试
- 完善个人项目
结果:
- 收获5个AI工程师offer
- 最终选择大厂,年薪$120K
经验总结:
- 早准备,早实践
- 实习经验很重要
- 项目质量 > 项目数量
- 面试准备要充分
结语:成为AI时代的建设者
回到刘润的那句话:”留下的人是什么?留下的还是程序员。关键是你是不是在头部。”
AI软件工程师不是一个岗位,而是一种能力组合,是一种思维方式,更是一种对未来的投资。
记住这些核心原则:
- 持续学习是唯一的护城河
- AI领域变化太快
- 今天的技能明天可能过时
- 学习能力比已有知识更重要
- 从知识工作者到判断力工作者
- AI可以生成代码,但无法做出正确的技术决策
- 培养技术品味和承担责任的能力
- 这是人类相对于AI的核心竞争力
- 拥抱不确定性
- 这是最好的时代,也是最具挑战的时代
- 变化中蕴藏巨大机会
- 热爱不确定性的人才能获得成功
- 行动大于完美
- 不要等到”准备好了”才开始
- 边学边做,快速迭代
- 完成比完美更重要
最后的行动召唤:
def your_ai_journey():
today = datetime.now()
# 第一步:选择一个学习资源,今天就开始
start_learning()
# 第二步:定下第一个小目标(30天内)
set_goal("完成一个机器学习项目")
# 第三步:找到学习伙伴或社区
join_community()
# 第四步:记录你的学习过程
start_blogging()
# 第五步:永不停止
while True:
learn()
build()
share()
improve()
return "成为AI时代的建设者"
# 现在就开始!
your_ai_journey()
结论与关键要点
核心洞察
- 拥抱长期不确定性:中美竞争将持续5-20年,不要期待短期内”熬过去”,而要将其视为机遇期
- 成为头部工程师:在AI时代,头部工程师依然是最有价值的群体,关键是要掌握底层技术,而不是做”头脑里的体力劳动”
- 培养判断力而非积累知识:知识已经廉价化,未来的竞争力在于判断力——包括品味和担责能力
实践启示
- 不要焦虑:热爱不确定性的人才能在变化中获得成功
- 持续学习底层技术:即使AI能编程,懂AI的程序员依然是最抢手的人才
- 从知识搬运到价值判断:从单纯的知识工作者转型为具有判断力的工作者
- 建立品味和责任感:这是AI无法替代的人类独特价值
致敬与展望
刘润的老同事在微软已经工作23年,这本身就是一个传奇。在这个充满变化的时代,职业发展不再是简单的线性成长,而是需要在动荡中找到自己的定位。正如刘润所说:”这个世界只要不变化,你就没有机会。”
相关参考
概念来源
- 知识工作者(Knowledge Worker):彼得·德鲁克(Peter Drucker)提出
- 判断力工作者(Judgment Worker):刘润在本次分享中提出的新概念
延伸思考
- 中美科技竞争格局分析
- AI时代的职业技能转型
- 从知识经济到判断力经济的范式转变
- 大国竞争下的个人职业发展策略
政策背景
- 美国针对”敌对国家”的数据保护法案
- 中美科技脱钩的长期趋势
这条路不会轻松,但绝对值得。AI革命才刚刚开始,而你,可以成为这场革命的建设者而非旁观者。
你的AI工程师之路,从今天开始! 🚀
本总结基于刘润2026年1月30日在微软上海园区职业生涯发展日的分享内容整理
