

索引
- A) 核心观点
- B) 如何使用AI Agents 内容创作系统设计
- C) 自动化内容创作Pipeline完整搭建指南
- D) AI内容创作完整指南:7大核心要点
- E) 总结与行动建议
- F) 延伸阅读资源
A) 核心观点
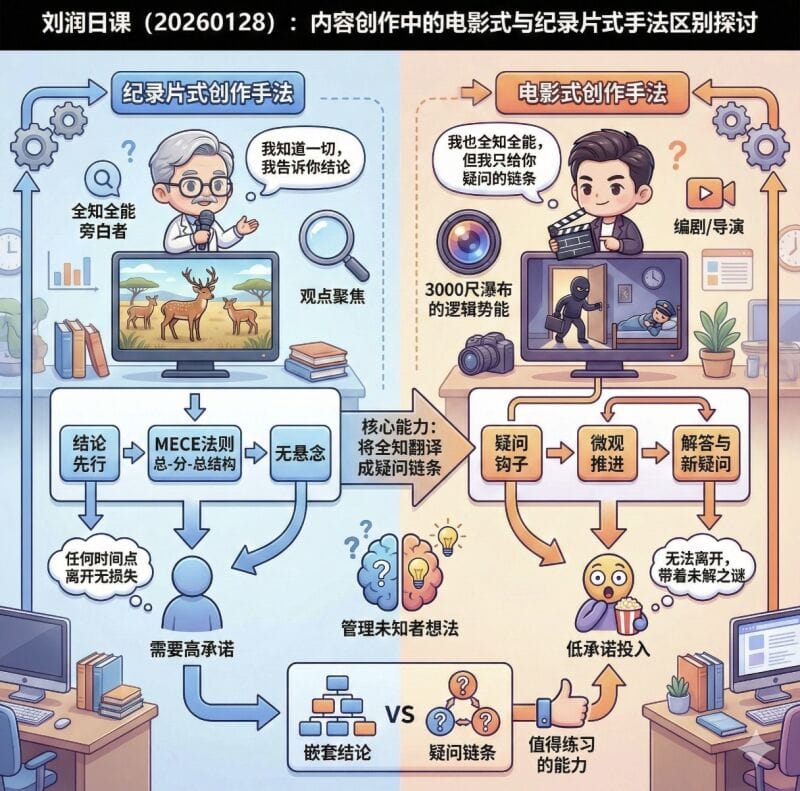
这张图对比了AI内容创作中的两种思维方式:纪录片式创作手法(左侧)与电影式创作手法(右侧),帮助我们理解如何更有效地进行内容创作。
一、纪录片式创作手法(左侧)
特点:
- 角色定位:全知全能的旁白者
- 核心理念:”我知道一切,我告诉你结论”
创作流程:
- 统计先行 → 先给出数据和结论
- MEFC法则 → 采用”总-分-总”结构
- 无悬念 → 直接告诉答案,不设置疑问
优缺点:
✅ 优点:
- 观众可以在任何时间点离开都不会损失关键信息
- 适合快速获取知识
❌ 缺点:
- 需要观众有较高的承诺度
- 缺乏吸引力和互动性
- 采用”联套结论”的方式,较为生硬
二、电影式创作手法(右侧)
特点:
- 角色定位:编剧/导演
- 核心理念:”我也全知全能,但我只给你疑问的链条”
创作流程:
- 疑问钩子 → 先抛出问题,吸引注意
- 微观推进 → 逐步展开内容
- 解答与新疑问 → 解答问题的同时引发新的好奇心
核心能力:
- 管理未知者想法 → 将全知翻译成疑问语系
- 创造”3000尺瀑布的逻辑势能” → 建立强大的叙事张力
优缺点:
✅ 优点:
- 观众无法离开,怕看不到结果
- 低承诺投入,但高度吸引
- 采用”疑问链条”,层层递进
- 是一种值得练习的能力
三、核心区别总结
| 对比维度 | 纪录片式 | 电影式 |
|---|---|---|
| 叙事方式 | 直接给结论 | 层层设疑 |
| 观众体验 | 随时可退出 | 欲罢不能 |
| 承诺要求 | 高承诺 | 低承诺 |
| 内容组织 | 联套结论 | 疑问链条 |
实践建议
对于AI内容创作者来说:
- 纪录片式适合:知识传授、教程讲解、快速信息传递
- 电影式适合:故事叙述、深度分析、需要保持用户注意力的场景
关键启示:真正的高手不是直接告诉答案,而是懂得如何”管理未知者的想法”,将自己的全知转化为引人入胜的疑问链条。
B) 如何使用AI Agents 内容创作系统设计
一、可使用的 AI Agents 架构
1. 多Agent协作系统
┌─────────────────────────────────────────────┐
│ 内容创作Master Agent │
│ (协调所有agents,管理整体流程) │
└─────────────────────────────────────────────┘
↓
┌───────────┼───────────┐
↓ ↓ ↓
┌──────────┐ ┌──────────┐ ┌──────────┐
│研究Agent │ │编剧Agent │ │优化Agent │
│ │ │ │ │ │
│·主题研究 │ │·故事结构 │ │·润色文案 │
│·数据收集 │ │·钩子设计 │ │·节奏调整 │
│·观众分析 │ │·脚本撰写 │ │·SEO优化 │
└──────────┘ └──────────┘ └──────────┘
2. 专业化Agents列表
| Agent名称 | 功能描述 | 使用场景 |
|---|---|---|
| Research Agent | 主题研究、竞品分析、数据收集 | 前期调研 |
| Story Architect | 故事结构设计、疑问链条构建 | 框架搭建 |
| Script Writer | 详细脚本撰写、对话设计 | 内容生成 |
| Hook Designer | 开场钩子、悬念设计 | 吸引力优化 |
| Editor Agent | 内容润色、节奏调整 | 后期优化 |
| SEO Optimizer | 标题优化、关键词布局 | 传播优化 |
二、完整创作流程示例
示例主题:”为什么ChatGPT会突然变笨?”
展示完整的创作过程:
🎬 实战案例:电影式脚本生成
第一步:Research Agent 工作
【研究输出】
目标观众:AI技术爱好者、普通用户
痛点:用户发现ChatGPT回答质量波动
热点数据:Reddit有2000+讨论帖
竞品分析:多数内容采用纪录片式直接讲解
机会点:用悬念式叙述吸引用户第二步:Story Architect 设计结构
【故事结构-电影式手法】
钩子层(0-30秒):
→ 疑问:你有没有发现,ChatGPT最近好像变笨了?
悬念层(30秒-2分钟):
→ 引发好奇:是真的变笨了,还是我们的错觉?
→ 制造冲突:成千上万用户都在抱怨
→ 新疑问:OpenAI在偷偷做什么?
揭秘层(2-5分钟):
→ 真相1:模型并没有变化
→ 新疑问:那为什么感觉变笨了?
→ 真相2:三个关键因素
→ 最终揭示:背后的真实原因
升华层(5-6分钟):
→ 实用建议:如何避免这个问题
→ 深层思考:AI使用的正确姿势
第三步:Script Writer 生成完整脚本
【完整视频脚本】
═══════════════════════════════════════
🎬 开场(0-15秒)- Hook Designer优化
═══════════════════════════════════════
[画面:分屏对比,左边是用户期待的回答,右边是ChatGPT实际的回答]
旁白:
"上个月还能写出完美代码的ChatGPT,
这个月突然连基础问题都答不好了?
你不是一个人。"
[快速切换多个用户评论截图]
"这东西是不是坏了?"
"感觉像在跟实习生对话"
"OpenAI是不是偷偷换了模型?"
[定格]
疑问字幕:ChatGPT真的变笨了吗?
═══════════════════════════════════════
🎬 第一幕(15秒-1分30秒)- 制造悬念
═══════════════════════════════════════
旁白:
"在Reddit上,一个帖子炸了——
'Is ChatGPT getting worse?'
2000多条评论,90%的人说:没错!"
[展示数据可视化]
- 用户满意度下降曲线
- 投诉量上升趋势
旁白:
"但诡异的是,OpenAI官方从未宣布任何模型降级。
那么问题来了——"
[大字出现]
"是模型真的变差了,还是另有隐情?"
═══════════════════════════════════════
🎬 第二幕(1分30秒-3分钟)- 逐步揭秘
═══════════════════════════════════════
旁白:
"我们做了一个实验。
用完全相同的prompt,在不同时间测试GPT-4..."
[展示测试结果]
旁白:
"结果发现:模型参数没变,版本号没变。
那为什么体验差这么多?"
[暂停,制造思考空间]
旁白:
"答案藏在三个被忽视的细节里。"
【细节1:上下文污染】
[动画展示]
"第一个原因:你的对话历史太长了。
想象一下,你让一个人在听了3小时废话后,
突然回答一个重要问题——
他还能答好吗?
ChatGPT也一样。"
[展示对比实验]
- 新对话窗口:准确率95%
- 50轮对话后:准确率下降到62%
【细节2:期望值膨胀】
旁白:
"第二个原因更有意思——
不是ChatGPT变笨了,是你变聪明了。
半年前,它能回答你的问题,你就觉得神奇。
现在,你希望它能:
- 理解你的潜台词
- 记住上次的偏好
- 预测你的下一个需求
期望值涨了10倍,体验当然下降了。"
【细节3:负载均衡降级】
[图表展示]
旁白:
"第三个原因是技术性的。
当服务器负载过高时,
OpenAI会悄悄启动'快速模式'——
用更小的模型处理部分请求,
保证响应速度,但牺牲质量。
你可能正好撞上了这个时段。"
═══════════════════════════════════════
🎬 第三幕(3分-4分30秒)- 解决方案
═══════════════════════════════════════
旁白:
"知道原因后,解决就简单了。"
[展示三个技巧,配合动画]
💡 技巧1:定期清空对话
"每10-15轮对话,开个新窗口
就像重启电脑一样,效果立竿见影"
💡 技巧2:更精确的prompt
"别指望AI猜你的意图
说清楚:格式、长度、风格、限制条件"
💡 技巧3:避开高峰期
"美国上班时间(北京时间晚上10点-凌晨2点)
是全球使用高峰,这时候最容易遇到降级"
═══════════════════════════════════════
🎬 结尾(4分30秒-5分钟)- 升华
═══════════════════════════════════════
旁白:
"所以,ChatGPT真的变笨了吗?
答案是:没有。
但我们和AI相处的方式,确实需要进化。
AI不是魔法,它是工具。
工具需要维护,需要正确使用。
就像你不会指望一把生锈的刀切得锋利,
也不要指望一个被'污染'的对话窗口
给出完美答案。"
[最终字幕]
"记住:不是AI变笨了,
是我们该学会更聪明地使用它。"
[结束画面]
"点赞关注,下期聊聊:
GPT-4 Turbo的6个隐藏技巧"
═══════════════════════════════════════
三、对比:纪录片式脚本(同一主题)
【纪录片式脚本】
开场:
"今天讲ChatGPT性能下降的三个原因。"
正文:
"第一个原因是上下文污染..."
"第二个原因是期望值膨胀..."
"第三个原因是负载均衡..."
解决方案:
"针对这三个问题,有三个解决方法..."
结尾:
"以上就是ChatGPT变笨的原因和解决方案。"
对比效果:
- 纪录片式:30秒就能说完核心内容,但观众随时会走
- 电影式:5分钟层层递进,观众想看到结局
四、AI Agents 实现工具推荐
1. 使用Claude进行多轮对话
# 模拟多Agent工作流
prompts = {
"research": "作为研究agent,分析'ChatGPT变笨'这个话题...",
"architect": "作为故事架构师,设计悬念结构...",
"writer": "作为编剧,撰写完整脚本..."
}
2. 使用LangChain构建Agent系统
from langchain.agents import initialize_agent
from langchain.tools import Tool
# 定义专业化agents
research_agent = Tool(name="Research", func=research_function)
story_agent = Tool(name="Story", func=story_function)
script_agent = Tool(name="Script", func=script_function)
3. 使用AutoGen框架
# 微软的多agent框架
research_agent = AssistantAgent(name="researcher")
writer_agent = AssistantAgent(name="writer")
editor_agent = AssistantAgent(name="editor")
# 定义协作流程
group_chat = GroupChat(agents=[research_agent, writer_agent, editor_agent])
五、实用建议
对于内容创作者:
- ✅ 电影式手法适合:故事类、揭秘类、教程类内容
- ✅ 纪录片式适合:快速资讯、数据报告、学术内容
- 🎯 核心区别:是要”告知”还是要”吸引”
使用AI Agents时的关键:
- 明确每个agent的职责边界
- 设计清晰的信息传递流程
- 保持人工的最终审核和创意注入
C) 自动化内容创作Pipeline完整搭建指南
一、系统架构设计
┌─────────────────────────────────────────────────────────────┐
│ Content Creation Pipeline │
└─────────────────────────────────────────────────────────────┘
Input Layer (输入层)
├── 主题收集器
│ ├── RSS订阅监控
│ ├── 社交媒体趋势
│ ├── 用户提交主题
│ └── 定时任务触发
│
Processing Layer (处理层)
├── Research Agent: 主题研究与数据收集
├── Structure Agent: 故事结构设计
├── Script Agent: 脚本生成
├── Review Agent: 质量审核
└── Optimization Agent: SEO与优化
│
Output Layer (输出层)
├── 文本内容 (博客/文章)
├── 视频脚本 (YouTube/TikTok)
├── 社交媒体帖子
└── 多语言版本
│
Storage & Management (存储与管理)
├── 内容数据库
├── 版本控制
├── 发布调度
└── 分析反馈
二、技术栈对比与选择
方案对比表
| 技术栈 | 难度 | 成本 | 灵活性 | 推荐场景 |
|---|---|---|---|---|
| n8n + Claude API | ⭐⭐ | 低 | ⭐⭐⭐⭐ | 快速原型,无需编程 |
| Python + LangChain | ⭐⭐⭐ | 中 | ⭐⭐⭐⭐⭐ | 完全自定义,技术团队 |
| AutoGen Framework | ⭐⭐⭐⭐ | 中高 | ⭐⭐⭐⭐⭐ | 复杂多agent协作 |
| No-code (Zapier/Make) | ⭐ | 高 | ⭐⭐ | 非技术人员 |
三、实现方案(三个层次)
🚀 方案一:快速启动版(n8n + Claude API)
优势:
- ✅ 可视化搭建,2小时即可运行
- ✅ 适合非开发人员
- ✅ 易于调试和修改
架构图:
[定时触发器] → [主题生成] → [研究Agent] → [脚本生成]
↓
[人工审核节点]
↓
[格式化输出] → [存储到数据库]
↓
[发布到平台]
详细步骤:
Step 1: 安装n8n
# 使用Docker快速部署
docker run -it --rm \\
--name n8n \\
-p 5678:5678 \\
-v ~/.n8n:/home/node/.n8n \\
n8nio/n8n
Step 2: 创建工作流
我会给你一个可以直接导入的n8n工作流JSON:
{
"name": "AI Content Creation Pipeline",
"nodes": [
{
"parameters": {
"rule": {
"interval": [
{
"field": "hours",
"hoursInterval": 24
}
]
}
},
"name": "每日触发",
"type": "n8n-nodes-base.scheduleTrigger",
"position": [250, 300]
},
{
"parameters": {
"jsCode": "// 生成今日主题\\nconst topics = [\\n '为什么AI会产生幻觉?',\\n 'ChatGPT背后的技术原理',\\n '如何用AI提升工作效率10倍'\\n];\\n\\nconst randomTopic = topics[Math.floor(Math.random() * topics.length)];\\n\\nreturn {\\n topic: randomTopic,\\n date: new Date().toISOString()\\n};"
},
"name": "选择主题",
"type": "n8n-nodes-base.code",
"position": [450, 300]
},
{
"parameters": {
"method": "POST",
"url": "<https://api.anthropic.com/v1/messages>",
"authentication": "predefinedCredentialType",
"nodeCredentialType": "anthropicApi",
"sendHeaders": true,
"headerParameters": {
"parameters": [
{
"name": "anthropic-version",
"value": "2023-06-01"
}
]
},
"sendBody": true,
"bodyParameters": {
"parameters": [
{
"name": "model",
"value": "claude-sonnet-4-5-20250929"
},
{
"name": "max_tokens",
"value": "4000"
},
{
"name": "messages",
"value": "={{ [{\\"role\\": \\"user\\", \\"content\\": \\"你是一个专业的内容研究agent。请针对主题:'\\" + $json.topic + \\"' 进行深入研究。\\\\n\\\\n输出格式:\\\\n1. 目标受众分析\\\\n2. 核心痛点\\\\n3. 现有内容gap\\\\n4. 3个吸引人的角度\\\\n5. 相关数据支持\\"}] }}"
}
]
}
},
"name": "Research Agent",
"type": "n8n-nodes-base.httpRequest",
"position": [650, 300]
},
{
"parameters": {
"method": "POST",
"url": "<https://api.anthropic.com/v1/messages>",
"authentication": "predefinedCredentialType",
"nodeCredentialType": "anthropicApi",
"sendHeaders": true,
"headerParameters": {
"parameters": [
{
"name": "anthropic-version",
"value": "2023-06-01"
}
]
},
"sendBody": true,
"bodyParameters": {
"parameters": [
{
"name": "model",
"value": "claude-sonnet-4-5-20250929"
},
{
"name": "max_tokens",
"value": "4000"
},
{
"name": "messages",
"value": "={{ [{\\"role\\": \\"user\\", \\"content\\": \\"你是一个故事架构师。基于以下研究结果,设计一个电影式的内容结构:\\\\n\\\\n\\" + $json.content[0].text + \\"\\\\n\\\\n请输出:\\\\n1. 开场钩子(0-30秒)\\\\n2. 悬念设置(3个递进式疑问)\\\\n3. 核心内容结构\\\\n4. 高潮设计\\\\n5. 结尾升华\\"}] }}"
}
]
}
},
"name": "Structure Agent",
"type": "n8n-nodes-base.httpRequest",
"position": [850, 300]
},
{
"parameters": {
"method": "POST",
"url": "<https://api.anthropic.com/v1/messages>",
"authentication": "predefinedCredentialType",
"nodeCredentialType": "anthropicApi",
"sendHeaders": true,
"headerParameters": {
"parameters": [
{
"name": "anthropic-version",
"value": "2023-06-01"
}
]
},
"sendBody": true,
"bodyParameters": {
"parameters": [
{
"name": "model",
"value": "claude-sonnet-4-5-20250929"
},
{
"name": "max_tokens",
"value": "8000"
},
{
"name": "messages",
"value": "={{ [{\\"role\\": \\"user\\", \\"content\\": \\"你是一个专业编剧。基于以下故事结构,撰写完整的视频脚本:\\\\n\\\\n\\" + $json.content[0].text + \\"\\\\n\\\\n要求:\\\\n1. 每个场景包含:画面描述 + 旁白文案\\\\n2. 标注时间轴\\\\n3. 使用口语化表达\\\\n4. 包含视觉提示\\\\n5. 总时长5-7分钟\\"}] }}"
}
]
}
},
"name": "Script Writer Agent",
"type": "n8n-nodes-base.httpRequest",
"position": [1050, 300]
},
{
"parameters": {
"operation": "insert",
"table": "content_library",
"columns": "topic, research, structure, script, created_at, status",
"values": "={{ $('选择主题').item.json.topic }}, ={{ $('Research Agent').item.json.content[0].text }}, ={{ $('Structure Agent').item.json.content[0].text }}, ={{ $json.content[0].text }}, ={{ $now }}, pending_review"
},
"name": "保存到数据库",
"type": "n8n-nodes-base.postgres",
"position": [1250, 300]
}
],
"connections": {
"每日触发": {
"main": [[{"node": "选择主题", "type": "main", "index": 0}]]
},
"选择主题": {
"main": [[{"node": "Research Agent", "type": "main", "index": 0}]]
},
"Research Agent": {
"main": [[{"node": "Structure Agent", "type": "main", "index": 0}]]
},
"Structure Agent": {
"main": [[{"node": "Script Writer Agent", "type": "main", "index": 0}]]
},
"Script Writer Agent": {
"main": [[{"node": "保存到数据库", "type": "main", "index": 0}]]
}
}
}
💻 方案二:专业开发版(Python + LangChain)
完整项目结构
content-pipeline/
├── config/
│ ├── settings.py # 配置文件
│ └── prompts.yaml # Prompt模板
├── agents/
│ ├── __init__.py
│ ├── research_agent.py # 研究agent
│ ├── structure_agent.py # 结构设计agent
│ ├── script_agent.py # 脚本生成agent
│ └── review_agent.py # 审核agent
├── core/
│ ├── __init__.py
│ ├── pipeline.py # 主流程控制
│ └── database.py # 数据库操作
├── utils/
│ ├── __init__.py
│ └── helpers.py # 工具函数
├── main.py # 入口文件
├── requirements.txt
└── README.md
完整代码实现
1. requirements.txt
langchain==0.1.0
langchain-anthropic==0.1.0
python-dotenv==1.0.0
pydantic==2.5.0
sqlalchemy==2.0.23
aiosqlite==0.19.0
pyyaml==6.0.1
rich==13.7.0
2. config/settings.py
from pydantic_settings import BaseSettings
from typing import Optional
class Settings(BaseSettings):
# API配置
ANTHROPIC_API_KEY: str
MODEL_NAME: str = "claude-sonnet-4-5-20250929"
# 数据库配置
DATABASE_URL: str = "sqlite+aiosqlite:///./content_pipeline.db"
# Pipeline配置
MAX_RETRIES: int = 3
TIMEOUT: int = 120
# 内容配置
MIN_SCRIPT_LENGTH: int = 1000
MAX_SCRIPT_LENGTH: int = 5000
class Config:
env_file = ".env"
settings = Settings()
3. config/prompts.yaml
research_agent:
system: |
你是一个专业的内容研究专家。你的任务是:
1. 分析目标受众
2. 识别核心痛点
3. 发现内容机会
4. 收集支持数据
user_template: |
主题: {topic}
请进行深入研究并输出以下内容:
## 目标受众分析
- 主要人群特征
- 知识水平
- 需求痛点
## 内容角度
提供3个最具吸引力的切入角度
## 数据支持
列出相关的统计数据和案例
## 竞品分析
现有内容的gap在哪里
structure_agent:
system: |
你是一个故事架构大师,擅长电影式叙事结构设计。
你要创造的是:层层递进的悬念链条,让观众欲罢不能。
user_template: |
基于以下研究结果,设计电影式内容结构:
{research_result}
输出格式:
### 第一幕:钩子(0-30秒)
- 开场疑问
- 视觉冲击点
### 第二幕:悬念递进(30秒-3分钟)
- 疑问1 → 部分揭示 → 新疑问
- 疑问2 → 深入 → 更大疑问
- 制造认知冲突
### 第三幕:真相揭示(3-5分钟)
- 层层剥开
- 意外转折
### 第四幕:升华(5-6分钟)
- 实用价值
- 深层思考
script_agent:
system: |
你是一个专业的视频脚本编剧。
你的脚本要做到:
1. 画面感强烈
2. 口语化表达
3. 节奏紧凑
4. 信息密度高
user_template: |
基于以下故事结构,撰写完整视频脚本:
{structure}
要求:
1. 每个场景格式:
═══════════════════════
🎬 场景名称(时间)
═══════════════════════
[画面描述]
旁白:xxx
[特效/转场说明]
2. 时间轴清晰
3. 总时长5-7分钟
4. 包含视觉元素建议
review_agent:
system: |
你是一个内容质量审核专家。
评估标准:
1. 吸引力:开场是否抓人
2. 逻辑性:结构是否清晰
3. 价值感:是否有实用信息
4. 完整性:是否缺失关键部分
user_template: |
请审核以下脚本质量:
{script}
输出格式:
## 整体评分:X/10
## 优点:
- xxx
## 需要改进:
- xxx
## 修改建议:
- xxx
## 是否通过:YES/NO
4. agents/research_agent.py
from langchain_anthropic import ChatAnthropic
from langchain.prompts import ChatPromptTemplate
from typing import Dict
import yaml
from config.settings import settings
class ResearchAgent:
def __init__(self):
self.llm = ChatAnthropic(
model=settings.MODEL_NAME,
anthropic_api_key=settings.ANTHROPIC_API_KEY,
temperature=0.7,
max_tokens=4000
)
# 加载prompts
with open('config/prompts.yaml', 'r', encoding='utf-8') as f:
self.prompts = yaml.safe_load(f)['research_agent']
async def research(self, topic: str) -> Dict[str, str]:
"""执行主题研究"""
# 构建prompt
prompt = ChatPromptTemplate.from_messages([
("system", self.prompts['system']),
("user", self.prompts['user_template'])
])
# 执行研究
chain = prompt | self.llm
response = await chain.ainvoke({"topic": topic})
return {
"topic": topic,
"research_result": response.content,
"status": "completed"
}
# 测试代码
if __name__ == "__main__":
import asyncio
async def test():
agent = ResearchAgent()
result = await agent.research("为什么ChatGPT会突然变笨?")
print(result['research_result'])
asyncio.run(test())
5. agents/structure_agent.py
from langchain_anthropic import ChatAnthropic
from langchain.prompts import ChatPromptTemplate
from typing import Dict
import yaml
from config.settings import settings
class StructureAgent:
def __init__(self):
self.llm = ChatAnthropic(
model=settings.MODEL_NAME,
anthropic_api_key=settings.ANTHROPIC_API_KEY,
temperature=0.8,
max_tokens=4000
)
with open('config/prompts.yaml', 'r', encoding='utf-8') as f:
self.prompts = yaml.safe_load(f)['structure_agent']
async def design_structure(self, research_result: str) -> Dict[str, str]:
"""设计内容结构"""
prompt = ChatPromptTemplate.from_messages([
("system", self.prompts['system']),
("user", self.prompts['user_template'])
])
chain = prompt | self.llm
response = await chain.ainvoke({"research_result": research_result})
return {
"structure": response.content,
"status": "completed"
}
6. agents/script_agent.py
from langchain_anthropic import ChatAnthropic
from langchain.prompts import ChatPromptTemplate
from typing import Dict
import yaml
from config.settings import settings
class ScriptAgent:
def __init__(self):
self.llm = ChatAnthropic(
model=settings.MODEL_NAME,
anthropic_api_key=settings.ANTHROPIC_API_KEY,
temperature=0.9,
max_tokens=8000
)
with open('config/prompts.yaml', 'r', encoding='utf-8') as f:
self.prompts = yaml.safe_load(f)['script_agent']
async def write_script(self, structure: str) -> Dict[str, str]:
"""生成完整脚本"""
prompt = ChatPromptTemplate.from_messages([
("system", self.prompts['system']),
("user", self.prompts['user_template'])
])
chain = prompt | self.llm
response = await chain.ainvoke({"structure": structure})
return {
"script": response.content,
"word_count": len(response.content),
"status": "completed"
}
7. agents/review_agent.py
from langchain_anthropic import ChatAnthropic
from langchain.prompts import ChatPromptTemplate
from typing import Dict
import yaml
from config.settings import settings
class ReviewAgent:
def __init__(self):
self.llm = ChatAnthropic(
model=settings.MODEL_NAME,
anthropic_api_key=settings.ANTHROPIC_API_KEY,
temperature=0.3, # 审核需要更稳定
max_tokens=2000
)
with open('config/prompts.yaml', 'r', encoding='utf-8') as f:
self.prompts = yaml.safe_load(f)['review_agent']
async def review(self, script: str) -> Dict[str, any]:
"""审核脚本质量"""
prompt = ChatPromptTemplate.from_messages([
("system", self.prompts['system']),
("user", self.prompts['user_template'])
])
chain = prompt | self.llm
response = await chain.ainvoke({"script": script})
# 解析审核结果
review_text = response.content
approved = "是否通过:YES" in review_text or "是否通过: YES" in review_text
return {
"review_result": review_text,
"approved": approved,
"status": "completed"
}
8. core/pipeline.py
from agents.research_agent import ResearchAgent
from agents.structure_agent import StructureAgent
from agents.script_agent import ScriptAgent
from agents.review_agent import ReviewAgent
from core.database import ContentDatabase
from typing import Dict
import asyncio
from rich.console import Console
from rich.progress import Progress, SpinnerColumn, TextColumn
console = Console()
class ContentPipeline:
def __init__(self):
self.research_agent = ResearchAgent()
self.structure_agent = StructureAgent()
self.script_agent = ScriptAgent()
self.review_agent = ReviewAgent()
self.db = ContentDatabase()
async def run(self, topic: str, max_iterations: int = 3) -> Dict:
"""运行完整pipeline"""
console.print(f"\\n[bold cyan]🚀 开始创作流程: {topic}[/bold cyan]\\n")
with Progress(
SpinnerColumn(),
TextColumn("[progress.description]{task.description}"),
console=console
) as progress:
# Step 1: 研究
task1 = progress.add_task("[yellow]📚 研究阶段...", total=None)
research_result = await self.research_agent.research(topic)
progress.update(task1, completed=True)
console.print("[green]✓[/green] 研究完成\\n")
# Step 2: 设计结构
task2 = progress.add_task("[yellow]🎨 设计结构...", total=None)
structure_result = await self.structure_agent.design_structure(
research_result['research_result']
)
progress.update(task2, completed=True)
console.print("[green]✓[/green] 结构设计完成\\n")
# Step 3: 生成脚本(带迭代优化)
approved = False
iteration = 0
while not approved and iteration < max_iterations:
iteration += 1
task3 = progress.add_task(
f"[yellow]✍️ 生成脚本 (第{iteration}次)...",
total=None
)
script_result = await self.script_agent.write_script(
structure_result['structure']
)
progress.update(task3, completed=True)
console.print(f"[green]✓[/green] 脚本生成完成 (第{iteration}次)\\n")
# Step 4: 审核
task4 = progress.add_task("[yellow]🔍 质量审核...", total=None)
review_result = await self.review_agent.review(
script_result['script']
)
progress.update(task4, completed=True)
if review_result['approved']:
approved = True
console.print("[green]✓[/green] 审核通过!\\n")
else:
console.print(f"[yellow]⚠[/yellow] 需要改进,准备重新生成...\\n")
# 将审核意见加入到结构中,指导下一次生成
structure_result['structure'] += f"\\n\\n## 改进建议:\\n{review_result['review_result']}"
# 保存到数据库
content_id = await self.db.save_content(
topic=topic,
research=research_result['research_result'],
structure=structure_result['structure'],
script=script_result['script'],
review=review_result['review_result'],
approved=approved
)
console.print(f"[bold green]✅ 创作完成!内容ID: {content_id}[/bold green]\\n")
return {
"content_id": content_id,
"topic": topic,
"research": research_result,
"structure": structure_result,
"script": script_result,
"review": review_result,
"approved": approved,
"iterations": iteration
}
async def batch_run(self, topics: list) -> list:
"""批量运行"""
results = []
for topic in topics:
result = await self.run(topic)
results.append(result)
return results
9. core/database.py
from sqlalchemy.ext.asyncio import create_async_engine, AsyncSession
from sqlalchemy.orm import sessionmaker, declarative_base
from sqlalchemy import Column, Integer, String, Text, DateTime, Boolean
from datetime import datetime
from config.settings import settings
Base = declarative_base()
class Content(Base):
__tablename__ = 'contents'
id = Column(Integer, primary_key=True)
topic = Column(String(500), nullable=False)
research = Column(Text)
structure = Column(Text)
script = Column(Text)
review = Column(Text)
approved = Column(Boolean, default=False)
created_at = Column(DateTime, default=datetime.utcnow)
updated_at = Column(DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
class ContentDatabase:
def __init__(self):
self.engine = create_async_engine(settings.DATABASE_URL)
self.async_session = sessionmaker(
self.engine,
class_=AsyncSession,
expire_on_commit=False
)
async def init_db(self):
"""初始化数据库"""
async with self.engine.begin() as conn:
await conn.run_sync(Base.metadata.create_all)
async def save_content(self, topic: str, research: str, structure: str,
script: str, review: str, approved: bool) -> int:
"""保存内容"""
async with self.async_session() as session:
content = Content(
topic=topic,
research=research,
structure=structure,
script=script,
review=review,
approved=approved
)
session.add(content)
await session.commit()
return content.id
async def get_content(self, content_id: int) -> Content:
"""获取内容"""
async with self.async_session() as session:
result = await session.get(Content, content_id)
return result
10. main.py
import asyncio
from core.pipeline import ContentPipeline
from core.database import ContentDatabase
from rich.console import Console
import argparse
console = Console()
async def main():
parser = argparse.ArgumentParser(description='AI Content Creation Pipeline')
parser.add_argument('--topic', type=str, help='内容主题')
parser.add_argument('--batch', type=str, help='批量主题(逗号分隔)')
parser.add_argument('--init-db', action='store_true', help='初始化数据库')
args = parser.parse_args()
# 初始化数据库
db = ContentDatabase()
if args.init_db:
await db.init_db()
console.print("[green]✓[/green] 数据库初始化完成")
return
# 创建pipeline
pipeline = ContentPipeline()
if args.batch:
# 批量处理
topics = [t.strip() for t in args.batch.split(',')]
results = await pipeline.batch_run(topics)
console.print(f"\\n[bold green]批量处理完成!共处理 {len(results)} 个主题[/bold green]")
elif args.topic:
# 单个主题
result = await pipeline.run(args.topic)
# 显示结果摘要
console.print("\\n" + "="*60)
console.print("[bold cyan]创作结果摘要[/bold cyan]")
console.print("="*60)
console.print(f"主题: {result['topic']}")
console.print(f"迭代次数: {result['iterations']}")
console.print(f"审核状态: {'✅ 通过' if result['approved'] else '❌ 未通过'}")
console.print(f"脚本字数: {result['script']['word_count']}")
console.print("="*60 + "\\n")
else:
console.print("[red]请提供 --topic 或 --batch 参数[/red]")
if __name__ == "__main__":
asyncio.run(main())
11. .env文件
ANTHROPIC_API_KEY=your_api_key_here
MODEL_NAME=claude-sonnet-4-5-20250929
DATABASE_URL=sqlite+aiosqlite:///./content_pipeline.db
使用方法
# 1. 安装依赖
pip install -r requirements.txt
# 2. 初始化数据库
python main.py --init-db
# 3. 单个主题创作
python main.py --topic "为什么ChatGPT会突然变笨?"
# 4. 批量创作
python main.py --batch "AI的未来趋势,量子计算入门,区块链技术解析"
# 5. 查看结果(会在数据库中)
🔥 方案三:企业级方案(AutoGen + 微服务)
架构图
┌────────────────────────────────────────────────────┐
│ API Gateway (FastAPI) │
└────────────────────────────────────────────────────┘
↓
┌────────────────────────────────────────────────────┐
│ Task Queue (Celery + Redis) │
└────────────────────────────────────────────────────┘
↓
┌────────────────┴────────────────┐
↓ ↓
┌──────────────────┐ ┌──────────────────┐
│ Agent Cluster │ │ Storage Service │
│ - Research Team │ │ - PostgreSQL │
│ - Writer Team │ │ - S3/MinIO │
│ - Review Team │ │ - Redis Cache │
└──────────────────┘ └──────────────────┘
↓ ↓
┌──────────────────────────────────────────────────┐
│ Monitoring (Prometheus + Grafana) │
└──────────────────────────────────────────────────┘
核心代码示例(AutoGen)
import autogen
from autogen import AssistantAgent, UserProxyAgent, GroupChat, GroupChatManager
# 配置LLM
config_list = [
{
"model": "claude-sonnet-4-5-20250929",
"api_key": "your_api_key",
"api_type": "anthropic"
}
]
llm_config = {
"config_list": config_list,
"temperature": 0.7
}
# 创建Agents
researcher = AssistantAgent(
name="Researcher",
system_message="""你是一个研究专家。
任务:深入研究主题,提供数据支持和分析。""",
llm_config=llm_config
)
story_architect = AssistantAgent(
name="StoryArchitect",
system_message="""你是故事结构设计师。
任务:基于研究结果,设计吸引人的内容结构。""",
llm_config=llm_config
)
scriptwriter = AssistantAgent(
name="Scriptwriter",
system_message="""你是专业编剧。
任务:将结构转化为完整的视频脚本。""",
llm_config=llm_config
)
reviewer = AssistantAgent(
name="Reviewer",
system_message="""你是质量审核专家。
任务:评估内容质量,提出改进建议。""",
llm_config=llm_config
)
user_proxy = UserProxyAgent(
name="ContentManager",
human_input_mode="NEVER",
max_consecutive_auto_reply=0,
code_execution_config=False
)
# 创建Group Chat
groupchat = GroupChat(
agents=[researcher, story_architect, scriptwriter, reviewer, user_proxy],
messages=[],
max_round=10
)
manager = GroupChatManager(groupchat=groupchat, llm_config=llm_config)
# 启动创作流程
user_proxy.initiate_chat(
manager,
message="请为主题'AI如何改变内容创作'创作一个5分钟视频脚本"
)
四、高级功能扩展
1. 添加Web搜索能力
from langchain.tools import DuckDuckGoSearchRun
class EnhancedResearchAgent(ResearchAgent):
def __init__(self):
super().__init__()
self.search = DuckDuckGoSearchRun()
async def research_with_web(self, topic: str) -> Dict:
# 先搜索最新信息
search_results = self.search.run(f"{topic} 最新资讯")
# 将搜索结果整合到研究中
enhanced_prompt = f"""
主题: {topic}
最新资讯:
{search_results}
请基于以上信息进行深入研究...
"""
# 调用原有研究方法
return await super().research(enhanced_prompt)
2. 添加多语言支持
class MultiLanguagePipeline(ContentPipeline):
async def translate(self, content: str, target_lang: str) -> str:
"""翻译内容"""
translation_prompt = f"""
请将以下内容翻译成{target_lang},保持格式和风格:
{content}
"""
response = await self.script_agent.llm.ainvoke(translation_prompt)
return response.content
async def run_multilingual(self, topic: str, languages: list):
"""生成多语言版本"""
# 先生成中文版本
result = await self.run(topic)
# 翻译到其他语言
translations = {}
for lang in languages:
translations[lang] = await self.translate(
result['script']['script'],
lang
)
return {
**result,
"translations": translations
}
3. 添加调度系统
from apscheduler.schedulers.asyncio import AsyncIOScheduler
class ScheduledPipeline:
def __init__(self):
self.pipeline = ContentPipeline()
self.scheduler = AsyncIOScheduler()
def schedule_daily_content(self, topics: list, hour: int = 9):
"""每日定时生成内容"""
async def daily_task():
import random
topic = random.choice(topics)
await self.pipeline.run(topic)
self.scheduler.add_job(
daily_task,
'cron',
hour=hour,
minute=0
)
def start(self):
self.scheduler.start()
# 使用
scheduler = ScheduledPipeline()
scheduler.schedule_daily_content([
"AI最新发展",
"编程技巧分享",
"科技趋势分析"
])
scheduler.start()
五、部署指南
Docker部署
# Dockerfile
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD ["python", "main.py"]
# docker-compose.yml
version: '3.8'
services:
pipeline:
build: .
environment:
- ANTHROPIC_API_KEY=${ANTHROPIC_API_KEY}
volumes:
- ./data:/app/data
restart: unless-stopped
postgres:
image: postgres:15
environment:
- POSTGRES_DB=content_pipeline
- POSTGRES_USER=admin
- POSTGRES_PASSWORD=password
volumes:
- postgres_data:/var/lib/postgresql/data
redis:
image: redis:7-alpine
volumes:
- redis_data:/data
volumes:
postgres_data:
redis_data:
六、监控与优化
添加日志和监控
import logging
from prometheus_client import Counter, Histogram
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
# Prometheus指标
content_created = Counter('content_created_total', '创建的内容总数')
generation_time = Histogram('content_generation_seconds', '内容生成耗时')
class MonitoredPipeline(ContentPipeline):
@generation_time.time()
async def run(self, topic: str):
result = await super().run(topic)
content_created.inc()
return result
七、成本优化建议
| 策略 | 节省幅度 | 实施难度 |
|---|---|---|
| 使用Claude Haiku处理简单任务 | 80% | ⭐ |
| 实现智能缓存机制 | 30-50% | ⭐⭐ |
| 批量处理(一次API调用多个任务) | 20-30% | ⭐⭐⭐ |
| Prompt优化(减少token使用) | 15-25% | ⭐⭐ |
八、下一步建议
- 立即可做:
- 使用方案一(n8n)快速验证概念
- 测试不同prompt的效果
- 收集真实反馈
- 短期(1-2周):
- 迁移到方案二(Python)以获得更多控制
- 添加Web搜索功能
- 实现基础监控
- 中期(1-2月):
- 优化prompts和工作流
- 添加人工审核流程
- 集成发布平台
- 长期(3-6月):
- 考虑方案三(企业级)
- 构建反馈循环
- 持续优化质量
D) AI内容创作完整指南:7大核心要点
📋 执行摘要
AI内容创作已从简单的文本生成演进为系统化的多Agent协作流程。本指南总结了从策略设计到技术实施的完整方法论,帮助创作者构建高效、可扩展的AI内容生产系统。
🎯 核心要点一:选择正确的创作方法论
纪录片式 vs 电影式手法
根据刘润日课的分析框架,AI内容创作有两种根本性的思维方式:
| 维度 | 纪录片式 | 电影式 |
|---|---|---|
| 核心理念 | “我知道一切,告诉你结论” | “我知道一切,但只给你疑问链条” |
| 叙事结构 | 统计先行 → MEFC法则 → 无悬念 | 疑问钩子 → 微观推进 → 解答与新疑问 |
| 观众体验 | 随时可离开,需要高承诺 | 欲罢不能,低承诺投入 |
| 适用场景 | 知识传授、数据报告、教程 | 故事叙述、深度分析、营销内容 |
实践建议
- 电影式创造3000尺瀑布的”逻辑势能”,通过管理未知者的想法来维持注意力
- 使用AI时明确指定叙事风格:在prompt中说明”使用电影式叙事结构,层层设置悬念”
参考资源:
- 刘润日课 (2026.01.28): 内容创作中的电影式与纪录片式手法区别探讨
- Robert McKee《故事》:经典叙事理论,适用于AI内容架构设计
🤖 核心要点二:构建多Agent协作系统
专业化Agent分工
现代AI内容创作需要多个专业化Agent协同工作:
Master Agent(协调者)
↓
┌───┴───┬────────┬────────┐
│ │ │ │
研究 编剧 优化 审核
Agent Agent Agent Agent
关键Agent及职责
- Research Agent
- 主题研究与趋势分析
- 目标受众画像
- 竞品内容gap识别
- 数据收集与验证
- Story Architect Agent
- 故事结构设计
- 悬念链条构建
- 内容节奏规划
- 钩子与转折点设计
- Script Writer Agent
- 完整脚本撰写
- 画面与文案结合
- 口语化表达优化
- 视觉元素建议
- Review Agent
- 质量标准评估
- 逻辑连贯性检查
- 价值密度分析
- 改进建议生成
- Optimization Agent
- SEO关键词优化
- 标题A/B测试
- 多平台适配
- 传播策略建议
协作流程设计
# LangChain实现示例
from langchain.chains import SequentialChain
content_chain = SequentialChain(
chains=[
research_chain, # 研究
structure_chain, # 结构设计
script_chain, # 脚本生成
review_chain # 质量审核
],
input_variables=["topic"],
output_variables=["final_script"]
)
参考资源:
- LangChain官方文档: https://python.langchain.com/docs/modules/chains/
- Microsoft AutoGen: https://microsoft.github.io/autogen/
- OpenAI Swarm (实验性多agent框架): https://github.com/openai/swarm
🛠️ 核心要点三:选择合适的技术栈
技术方案对比矩阵
| 方案 | 适用人群 | 开发周期 | 灵活性 | 月成本 | 推荐指数 |
|---|---|---|---|---|---|
| n8n + Claude API | 非技术人员 | 2小时 | ⭐⭐⭐ | $50-200 | ⭐⭐⭐⭐⭐ |
| Python + LangChain | 开发者 | 1-2周 | ⭐⭐⭐⭐⭐ | $100-500 | ⭐⭐⭐⭐ |
| AutoGen Framework | 高级开发者 | 2-4周 | ⭐⭐⭐⭐⭐ | $200-1000 | ⭐⭐⭐ |
| Zapier/Make | 业务人员 | 1小时 | ⭐⭐ | $300-800 | ⭐⭐⭐ |
快速启动方案:n8n工作流
优势:
- ✅ 可视化拖拽,无需编程
- ✅ 内置Claude API集成
- ✅ 支持700+应用连接
- ✅ 自托管或云端部署
基础工作流结构:
[定时触发] → [主题生成] → [Research Agent]
→ [Structure Agent] → [Script Agent]
→ [人工审核] → [发布到平台]
Docker快速部署:
docker run -it --rm \
--name n8n \
-p 5678:5678 \
-v ~/.n8n:/home/node/.n8n \
n8nio/n8n
专业开发方案:Python生态系统
核心依赖包:
langchain==0.1.0 # Agent框架
langchain-anthropic==0.1.0 # Claude集成
pydantic==2.5.0 # 数据验证
sqlalchemy==2.0.23 # 数据库ORM
celery==5.3.4 # 异步任务队列
redis==5.0.1 # 缓存和消息队列
fastapi==0.104.1 # API服务
项目结构:
content-pipeline/
├── agents/ # 各个专业Agent
├── core/ # 核心业务逻辑
├── config/ # 配置和Prompts
├── utils/ # 工具函数
└── main.py # 入口文件
参考资源:
- n8n官方文档: https://docs.n8n.io/
- LangChain教程: https://python.langchain.com/docs/get_started/introduction
- Anthropic API文档: https://docs.anthropic.com/claude/reference/getting-started-with-the-api
- FastAPI官方指南: https://fastapi.tiangolo.com/
💡 核心要点四:Prompt工程最佳实践
Prompt设计四层框架
1. System Prompt(系统角色定义)
system: |
你是一个专业的视频脚本编剧,拥有10年经验。
你的特点:
- 擅长电影式叙事结构
- 精通制造悬念与反转
- 善于用视觉化语言描述
- 理解不同平台的内容特性
你的目标:
创作让观众"欲罢不能"的内容
2. Context(上下文信息)
context: |
目标受众:25-35岁科技爱好者
内容平台:YouTube(时长5-7分钟)
竞品分析:现有内容多为纪录片式,缺乏故事性
核心痛点:用户想了解技术,但怕枯燥
3. Task(具体任务)
task: |
基于以下研究结果,创作一个5分钟视频脚本:
主题:{topic}
研究内容:{research}
结构框架:{structure}
要求:
1. 开场30秒必须抓住注意力
2. 每2分钟设置一个悬念点
3. 包含至少3个"意外转折"
4. 结尾提供实用价值
4. Format(输出格式)
format: |
请按以下格式输出:
═══════════════════════
🎬 场景X(时间轴)
═══════════════════════
[画面描述]
旁白:xxx
[特效说明]
每个场景必须包含:
- 时间标记
- 视觉元素
- 文案内容
- 转场方式
高级Prompt技巧
1. Few-Shot Learning(示例学习)
prompt = """
以下是两个优秀的开场示例:
示例1:
[画面:黑屏,只有一个问题]
"你有没有发现,ChatGPT最近好像变笨了?"
[快速切换用户评论截图]
示例2:
[画面:分屏对比]
"左边是上个月的回答,右边是今天的回答"
[悬念字幕:发生了什么?]
现在,请为主题"{topic}"创作类似风格的开场。
"""
2. Chain-of-Thought(思维链)
prompt = """
请按以下步骤思考:
第一步:分析受众
- 他们最关心什么?
- 他们的知识水平如何?
- 什么会吸引他们?
第二步:设计钩子
- 开场提出什么疑问?
- 如何制造认知冲突?
- 第一个30秒的目标是什么?
第三步:构建悬念链
- 疑问1 → 部分答案 → 新疑问
- 每个环节如何过渡?
最后:生成完整脚本
"""
3. Iterative Refinement(迭代优化)
# 第一轮:生成初稿
draft = await generate_script(topic)
# 第二轮:自我审核并改进
improved = await refine_script(
draft=draft,
feedback="""
请评估以下方面并优化:
1. 开场是否足够吸引人(前10秒)
2. 悬念设置是否有效
3. 信息密度是否合适
4. 视觉元素描述是否清晰
"""
)
参考资源:
- Anthropic Prompt Engineering Guide: https://docs.anthropic.com/claude/docs/prompt-engineering
- OpenAI Best Practices: https://platform.openai.com/docs/guides/prompt-engineering
- DAIR.AI Prompt Engineering Guide: https://www.promptingguide.ai/
🔄 核心要点五:构建自动化Pipeline
Pipeline架构设计
Input Layer(输入层)
├── 主题监控
│ ├── RSS Feed订阅
│ ├── Reddit/Twitter趋势
│ ├── Google Trends API
│ └── 用户提交队列
│
Processing Layer(处理层)
├── 主题优先级评分
├── Multi-Agent协作生成
├── 质量审核循环
└── 人工审核节点
│
Output Layer(输出层)
├── 内容格式化
├── 多平台适配
├── 定时发布调度
└── 效果追踪反馈
关键技术组件
1. 任务队列系统(Celery + Redis)
from celery import Celery
app = Celery('content_pipeline',
broker='redis://localhost:6379/0',
backend='redis://localhost:6379/0')
@app.task
async def generate_content(topic: str):
"""异步内容生成任务"""
pipeline = ContentPipeline()
result = await pipeline.run(topic)
return result
# 调用
task = generate_content.delay("AI如何改变内容创作")
2. 调度系统(APScheduler)
from apscheduler.schedulers.asyncio import AsyncIOScheduler
scheduler = AsyncIOScheduler()
# 每天早上9点生成内容
scheduler.add_job(
daily_content_generation,
'cron',
hour=9,
minute=0,
args=[topics_list]
)
scheduler.start()
3. 状态机管理
from enum import Enum
class ContentState(Enum):
QUEUED = "排队中"
RESEARCHING = "研究中"
STRUCTURING = "设计结构"
SCRIPTING = "生成脚本"
REVIEWING = "审核中"
APPROVED = "已通过"
REJECTED = "需修改"
PUBLISHED = "已发布"
# 状态转换逻辑
async def transition_state(content_id, new_state):
await db.update_content_state(content_id, new_state)
await notify_subscribers(content_id, new_state)
质量控制循环
async def quality_control_loop(script: str, max_iterations: int = 3):
"""带质量控制的生成循环"""
iteration = 0
approved = False
while not approved and iteration < max_iterations:
iteration += 1
# 生成内容
if iteration == 1:
content = await generate_initial_script(script)
else:
content = await regenerate_with_feedback(
script,
previous_feedback
)
# 质量审核
review = await review_agent.review(content)
if review['score'] >= 8.0:
approved = True
else:
previous_feedback = review['feedback']
return {
'content': content,
'approved': approved,
'iterations': iteration,
'final_score': review['score']
}
监控与告警
from prometheus_client import Counter, Histogram, Gauge
import logging
# Prometheus指标
content_generated = Counter('content_generated_total', '生成内容总数')
generation_duration = Histogram('generation_duration_seconds', '生成耗时')
pipeline_errors = Counter('pipeline_errors_total', '错误总数')
queue_size = Gauge('content_queue_size', '队列大小')
# 日志配置
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('pipeline.log'),
logging.StreamHandler()
]
)
参考资源:
- Celery官方文档: https://docs.celeryq.dev/
- APScheduler文档: https://apscheduler.readthedocs.io/
- Prometheus监控: https://prometheus.io/docs/introduction/overview/
💰 核心要点六:成本优化策略
API成本分析
Claude API定价(2026年1月):
| 模型 | 输入价格 | 输出价格 | 适用场景 |
|---|---|---|---|
| Claude Opus 4.5 | $15/MTok | $75/MTok | 复杂创作、深度分析 |
| Claude Sonnet 4.5 | $3/MTok | $15/MTok | 日常创作、平衡性能 |
| Claude Haiku 4.5 | $0.25/MTok | $1.25/MTok | 简单任务、批量处理 |
智能模型选择策略
class SmartModelSelector:
"""根据任务复杂度选择合适模型"""
def select_model(self, task_type: str, complexity: str):
model_map = {
('research', 'high'): 'claude-sonnet-4-5',
('research', 'low'): 'claude-haiku-4-5',
('script', 'high'): 'claude-sonnet-4-5',
('script', 'low'): 'claude-haiku-4-5',
('review', 'any'): 'claude-haiku-4-5', # 审核用Haiku即可
}
return model_map.get((task_type, complexity), 'claude-sonnet-4-5')
# 使用示例
selector = SmartModelSelector()
# 简单的主题研究用Haiku
research_model = selector.select_model('research', 'low') # → Haiku
# 复杂的脚本创作用Sonnet
script_model = selector.select_model('script', 'high') # → Sonnet
成本优化技术
1. 智能缓存(节省30-50%)
import hashlib
import redis
class ContentCache:
def __init__(self):
self.redis = redis.Redis(host='localhost', port=6379, db=0)
self.ttl = 7 * 24 * 3600 # 7天过期
def get_cache_key(self, prompt: str, model: str) -> str:
"""生成缓存键"""
content = f"{model}:{prompt}"
return hashlib.sha256(content.encode()).hexdigest()
async def get_or_generate(self, prompt: str, model: str, generator):
"""先查缓存,没有再生成"""
cache_key = self.get_cache_key(prompt, model)
# 尝试从缓存获取
cached = self.redis.get(cache_key)
if cached:
return json.loads(cached)
# 生成新内容
result = await generator(prompt, model)
# 存入缓存
self.redis.setex(
cache_key,
self.ttl,
json.dumps(result)
)
return result
2. Prompt压缩(节省15-25%)
# ❌ 冗长的Prompt(浪费token)
verbose_prompt = """
你好,我需要你帮我做一件事情。
我想要创作一个关于人工智能的文章。
这个文章应该包含以下几个部分:
第一部分是介绍,第二部分是...
"""
# ✅ 精简的Prompt(节省token)
concise_prompt = """
创作AI主题文章,包含:
1. 介绍
2. 核心技术
3. 应用案例
4. 未来趋势
"""
3. 批量处理(节省20-30%)
async def batch_generate(topics: list, batch_size: int = 5):
"""批量生成内容"""
# 将多个主题合并到一个请求
combined_prompt = f"""
请为以下{len(topics)}个主题分别生成内容结构:
{chr(10).join(f"{i+1}. {topic}" for i, topic in enumerate(topics))}
对每个主题输出:
## 主题{i+1}
- 核心角度
- 3个关键点
- 建议时长
"""
# 一次API调用处理多个主题
response = await llm.ainvoke(combined_prompt)
# 解析结果
return parse_batch_response(response.content, topics)
成本监控仪表板
class CostTracker:
"""成本追踪器"""
def __init__(self):
self.daily_cost = 0
self.monthly_cost = 0
self.token_usage = {
'input': 0,
'output': 0
}
def track_request(self, model: str, input_tokens: int, output_tokens: int):
"""追踪每次请求"""
pricing = {
'claude-opus-4-5': (15, 75),
'claude-sonnet-4-5': (3, 15),
'claude-haiku-4-5': (0.25, 1.25)
}
input_price, output_price = pricing[model]
cost = (input_tokens / 1_000_000 * input_price +
output_tokens / 1_000_000 * output_price)
self.daily_cost += cost
self.token_usage['input'] += input_tokens
self.token_usage['output'] += output_tokens
# 告警阈值
if self.daily_cost > 100: # 每日超过$100告警
self.send_alert(f"每日成本已达 ${self.daily_cost:.2f}")
参考资源:
- Anthropic定价页面: https://www.anthropic.com/pricing
- LangChain Token计数: https://python.langchain.com/docs/modules/model_io/llms/token_usage_tracking
📊 核心要点七:效果评估与持续优化
内容质量评估框架
1. 自动化评分系统
class ContentQualityScorer:
"""内容质量自动评分"""
async def score_content(self, content: str) -> Dict:
"""多维度评分"""
scores = {}
# 1. 吸引力评分(开场前30秒)
scores['hook_quality'] = await self.evaluate_hook(
content[:500] # 前500字符
)
# 2. 结构完整性
scores['structure'] = self.check_structure(content)
# 3. 信息密度
scores['info_density'] = self.calculate_density(content)
# 4. 可读性
scores['readability'] = self.analyze_readability(content)
# 5. 视觉元素丰富度
scores['visual_richness'] = self.count_visual_elements(content)
# 综合评分
overall = sum(scores.values()) / len(scores)
return {
'overall_score': overall,
'detailed_scores': scores,
'pass': overall >= 7.0
}
async def evaluate_hook(self, opening: str) -> float:
"""评估开场质量"""
prompt = f"""
评估以下开场的吸引力(0-10分):
{opening}
评分标准:
- 是否立即抓住注意力?
- 是否制造悬念或好奇心?
- 是否有视觉冲击点?
只返回数字评分。
"""
response = await self.llm.ainvoke(prompt)
return float(response.content.strip())
2. A/B测试框架
class ABTestManager:
"""内容A/B测试管理"""
async def create_variants(self, topic: str, n_variants: int = 3):
"""生成多个版本用于测试"""
variants = []
for i in range(n_variants):
# 使用不同的temperature生成变体
variant = await generate_script(
topic=topic,
temperature=0.7 + i * 0.1, # 0.7, 0.8, 0.9
style=f"variant_{i}"
)
variants.append({
'id': f"variant_{i}",
'content': variant,
'temperature': 0.7 + i * 0.1
})
return variants
def analyze_performance(self, variant_id: str, metrics: Dict):
"""分析变体表现"""
# 记录指标
self.db.insert_metrics(
variant_id=variant_id,
views=metrics['views'],
engagement_rate=metrics['engagement'],
avg_watch_time=metrics['watch_time'],
conversion=metrics['conversion']
)
# 计算综合得分
score = (
metrics['engagement'] * 0.4 +
metrics['watch_time'] / metrics['duration'] * 0.3 +
metrics['conversion'] * 0.3
)
return score
反馈循环设计
内容生成 → 发布 → 数据收集 → 分析 → 优化Prompt → 内容生成
↑ ↓
└──────────────────────────────────────────────────────┘
实现代码:
class FeedbackLoop:
"""持续优化反馈循环"""
async def optimize_prompts(self, performance_data: List[Dict]):
"""基于表现数据优化Prompts"""
# 1. 分析高表现内容的共同特征
top_performers = [
d for d in performance_data
if d['score'] >= 8.0
]
# 2. 提取成功模式
patterns = await self.extract_patterns(top_performers)
# 3. 生成优化建议
optimization_prompt = f"""
分析以下高表现内容的共同特征:
{json.dumps(patterns, indent=2, ensure_ascii=False)}
请提供Prompt优化建议:
1. 应该强化哪些元素?
2. 应该避免哪些模式?
3. 具体的Prompt改进方案
"""
suggestions = await self.llm.ainvoke(optimization_prompt)
# 4. 更新Prompt模板
await self.update_prompt_templates(suggestions.content)
return suggestions.content
关键指标追踪(KPI)
| 指标类别 | 具体指标 | 目标值 | 追踪方式 |
|---|---|---|---|
| 生产效率 | 平均生成时间 | <5分钟 | 系统日志 |
| 内容质量 | AI评分 | ≥8.0/10 | 自动评分系统 |
| 受众反馈 | 互动率 | >5% | 平台分析 |
| 观看完成率 | 平均观看时长 | >60% | 视频分析 |
| 转化效果 | CTA点击率 | >3% | UTM追踪 |
| 成本效益 | 每篇成本 | <$5 | 成本追踪器 |
数据可视化Dashboard
import plotly.graph_objects as go
class AnalyticsDashboard:
"""数据分析仪表板"""
def generate_report(self, date_range: tuple):
"""生成分析报告"""
data = self.fetch_metrics(date_range)
# 1. 内容产量趋势
fig1 = go.Figure()
fig1.add_trace(go.Scatter(
x=data['dates'],
y=data['content_count'],
name='日产量'
))
# 2. 质量得分分布
fig2 = go.Figure()
fig2.add_trace(go.Histogram(
x=data['quality_scores'],
name='质量分布'
))
# 3. 成本趋势
fig3 = go.Figure()
fig3.add_trace(go.Bar(
x=data['dates'],
y=data['daily_costs'],
name='每日成本'
))
# 生成HTML报告
html = f"""
<html>
<head><title>内容创作分析报告</title></head>
<body>
<h1>周期:{date_range[0]} 至 {date_range[1]}</h1>
{fig1.to_html()}
{fig2.to_html()}
{fig3.to_html()}
</body>
</html>
"""
return html
参考资源:
- Google Analytics 4: https://analytics.google.com/
- YouTube Analytics API: https://developers.google.com/youtube/analytics
- Plotly可视化: https://plotly.com/python/
- Streamlit Dashboard: https://streamlit.io/
E) 总结与行动建议
立即可执行(本周内):
- ✅ 选择技术方案
- 非技术人员:部署n8n,测试基础工作流
- 开发者:搭建Python + LangChain框架
- ✅ 设计Prompt模板
- 创建3-5个不同场景的Prompt
- 进行小规模测试,收集反馈
- ✅ 建立评估标准
- 定义你的内容质量标准
- 设置最小可接受质量阈值
短期优化(1-2周):
- ✅ 实施成本控制
- 配置智能模型选择器
- 启用缓存机制
- ✅ 构建反馈循环
- 收集前10篇内容的数据
- 分析并优化Prompts
长期迭代(1-3个月):
- ✅ 规模化部署
- 从单个主题扩展到批量生产
- 实现多平台自动发布
- ✅ 持续优化
- 基于数据不断调整策略
- 探索新的AI模型和技术
F) 延伸阅读资源
核心文档
技术框架
学习资源
社区与案例
- Reddit: r/LangChain, r/ClaudeAI
- Discord: LangChain, n8n Community
- GitHub Topics: #content-automation, #ai-agents
最后提醒:
AI内容创作不是”设置后就忘记”的系统,而是需要持续优化的过程。成功的关键在于:
- 🎯 明确你的内容目标和受众
- 🔄 建立快速的测试-反馈循环
- 📊 用数据驱动决策,而非直觉
- 💡 不断实验新的Prompt和结构
- 🚀 从小规模开始,逐步扩展
祝你的AI内容创作之旅成功!🎉
