

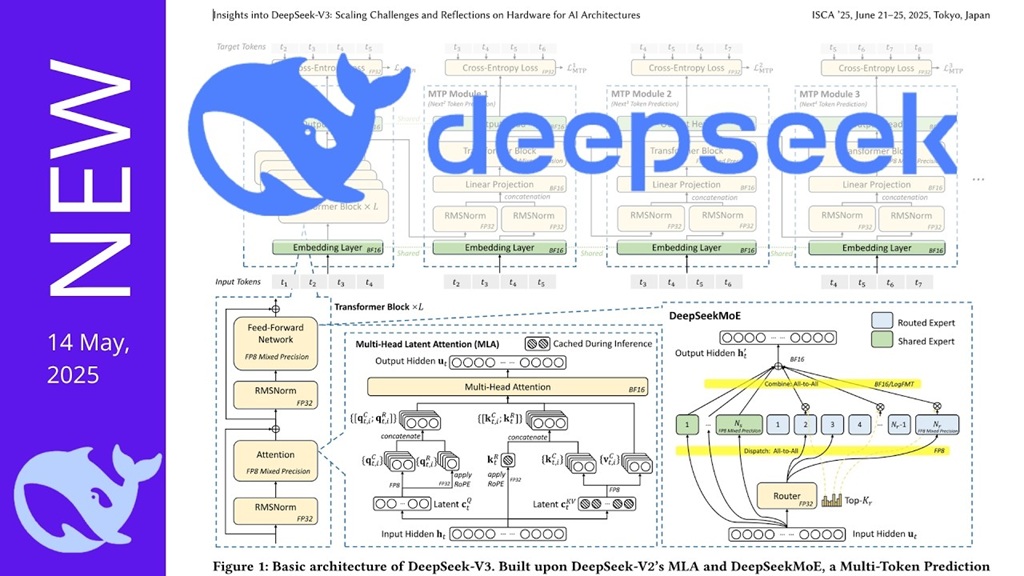
Introduction
On May 14, 2025, DeepSeek published a groundbreaking paper detailing the technological advancements behind their next generation of language models. This video breaks down the key innovations that have enabled DeepSeek, despite being a smaller company with fewer resources than tech giants, to develop highly competitive models through smart optimization rather than raw computing power. The presenter highlights how DeepSeek’s Version 3 model serves as the foundation for their upcoming R2 (Reasoning 2) model, demonstrating that effective software-hardware co-design can enable cost-efficient training of large language models even for smaller teams.
About DeepSeek R2 (future release)
An Overview of DeepSeek’s Upcoming R2 (Reasoning 2) Model
Current Status
Based on the information and additional insights from recent news, the overview of DeepSeek’s upcoming R2 model.
Foundation and Development
DeepSeek’s Version 3 model serves as the base model for the upcoming R2 (Reasoning 2) model. The technological innovations detailed in the May 14, 2025 paper provide the foundation for R2’s development:
- Multi-Head Latent Attention (MLA): This architecture significantly reduces memory requirements by compressing key-value representations into a smaller latent vector space.
- Advanced Mixture of Experts (MoE): DeepSeek has further developed their MoE approach with fine-grain expert segmentation and shared expert isolation, enabling them to scale to 671 billion parameters while keeping training costs manageable.
- Multi-Token Prediction (MTP) Framework: This allows the model to predict multiple future tokens simultaneously, improving inference speed with a 90% acceptance rate for second token predictions.
- FP8 Training and Quantization: Unlike competitors who only use quantization for inference, DeepSeek developed quantization techniques for the training process itself, making large model training more accessible.
Expected Release
DeepSeek originally planned to release R2 in early May 2025, but according to reports from Reuters and other sources, the company is now accelerating the launch schedule to release it “as early as possible.” The exact release date hasn’t been announced yet.
Anticipated Capabilities
Based on available information, DeepSeek R2 is expected to feature:
- Enhanced coding capabilities – R2 is designed to produce “better coding” compared to its predecessor
- Multilingual reasoning – Unlike R1 which primarily reasoned in English, R2 is expected to reason in multiple languages
- Advanced AI reasoning – Building on R1’s success, R2 aims to offer improved reasoning capabilities
Technical Specifications
According to rumors, DeepSeek reportedly trained the R2 model on 5.2 petabytes of high-end data, including specialized information on finance, law, and patents. The training was reportedly conducted using Huawei Ascend 910B chips.
Video About An Overview of DeepSeek’s Upcoming R2:
Related Section Analysis of the Video
Multi-Head Latent Attention (MLA) Architecture
DeepSeek has implemented Multi-Head Latent Attention (MLA) in their model architecture, which compresses the key-value representation of all attention heads into a smaller latent vector space using a projection matrix that is jointly trained with the LLM. During inference, only the latent vector needs to be cached, significantly reducing memory consumption compared to storing the key-value cache for all attention heads.
The efficiency of this approach is demonstrated in a performance benchmark where DeepSeek Version 3 with MLA requires only 70K of key-value cache size per token, compared to Llama 3.145’s 516K and QN 2.572B’s 327K. This represents a dramatic reduction in memory requirements while maintaining performance.
Mixture of Experts (MoE) Development
DeepSeek has further developed their Mixture of Experts approach, which was initially explained in January 2024. Their implementation includes conventional top-2 routing plus fine-grain expert segmentation and shared expert isolation. This structure, with shared experts and routed experts, enables significant optimization.
Despite increasing the model size significantly from 236 billion parameters in Version 2 to 671 billion in Version 3, DeepSeek has managed to keep training costs per token relatively stable. This achievement is particularly impressive when compared to dense models like QN72B (which has less than a tenth of the parameters but comparable training costs) or Llama 405B (which has extremely high training costs per token).
Multi-Token Prediction (MTP) Framework
DeepSeek has implemented a Multi-Token Prediction framework to enhance model performance and improve inference speed. Rather than just using auto-regressive next token prediction, this approach allows the model to predict multiple future tokens at once.
The implementation involves multiple MTP models, each using a single layer that is much more lightweight than the full model, enabling parallel verification of multiple candidate tokens. While this approach slightly impacts accuracy, it significantly improves end-to-end generation latency. After extensive testing, DeepSeek achieved an impressive 90% acceptance rate for correctly predicting the second subsequent token.
FP8 Training and Communication Compression
Instead of applying quantization only during inference (like common approaches such as GPTQ or AWQ), DeepSeek developed a quantization technique for the training process itself. Through collaboration between their infrastructure and algorithmic teams, they created an “FP8 compatible training framework for mixture of expert models,” which they’ve made open source through their “deep jam” library.
For network communication in their current V3 model, DeepSeek employs low-precision compression with fine-grained FP8 quantization to reduce communication volume. They’ve also developed a new data type: a logarithmic floating point format (logFMTnBit) that maps activation from the original linear space to log space, making the distribution of activation more uniform and improving performance.
KTransformer Inference Engine
Increasingly popular “Ktransformer inference engine” that allows a complete Deep 43 model to run on a low-cost server equipped with a consumer GPU. This is a flexible Python-centric framework with a RESTful API compatible with OpenAI and Llama, featuring a simplified web UI. Performance comparisons show it generating 14 tokens per second compared to Llama CPP’s 4.5 tokens per second. The presenter notes this is open source with an Apache 2 license and supports Intel GPUs, including Intel ARC GPUs.
Market outlook about the upcoming DeepSeek’s R2
Market Position
DeepSeek’s R1 model, launched in January 2025, gained significant attention for its efficient use of resources while matching the performance of more expensive models like OpenAI’s o1. This triggered notable reactions in the market, including what some reports describe as a “$1 trillion-plus sell-off in global equities markets.”
The anticipated R2 release comes amid intensifying competition in the AI landscape. Since R1’s launch, OpenAI has released o3 and o4-mini models, cut prices, and Google’s Gemini has introduced discounted tiers. Meanwhile, in China, Alibaba recently unveiled its Qwen3 family of AI models, which the company claims surpasses DeepSeek’s R1 in multiple areas.
Recent Developments
While waiting for R2, DeepSeek has recently made other advances:
- In collaboration with Tsinghua University, DeepSeek introduced a novel approach for improving reasoning capabilities through a technique that combines “generative reward modelling (GRM) and self-principled critique tuning.”
- DeepSeek quietly released Prover-V2, an update to its specialized model designed for handling mathematics proofs. This model is built on top of the V3 architecture with 671 billion parameters.
The company has also announced an “open-source week” where it will release five new open-source repositories, including DeepGEMM, an FP8 GEMM library optimized for dense and Mixture of Experts computations.
What Makes R2 Significant
The upcoming R2 model represents DeepSeek’s approach to competing with much larger companies through smart optimization rather than raw computing power. As detailed in the video, DeepSeek’s innovations in architecture, training methodologies, and hardware-software co-design allow them to create competitive models at a fraction of the cost compared to tech giants.
If R2 follows the pattern established by previous DeepSeek models, it could potentially challenge the dominance of established players in the AI landscape while demonstrating that effective optimization can compensate for hardware limitations.
Conclusion
DeepSeek’s latest paper demonstrates how innovative approaches to AI architecture and optimization can level the playing field between resource-constrained startups and tech giants with vast computing resources. Their focus on intelligent optimization rather than raw computing power has enabled them to create competitive models while keeping costs manageable.
Key Takeaways
- Efficient Architecture Design: DeepSeek’s Multi-Head Latent Attention (MLA) dramatically reduces memory requirements, needing only 70K of key-value cache size per token compared to competitors’ 300K-500K.
- Cost-Effective Scaling: Despite increasing model size from 236B to 671B parameters, DeepSeek maintained similar training costs per token through optimization techniques that outperform even smaller dense models.
- Training Innovations: The company developed FP8 quantization techniques for training (not just inference), creating an open-source library that makes large model training more accessible.
- Faster Generation: Their Multi-Token Prediction framework achieves 90% accuracy in predicting second tokens, significantly improving generation speed through parallel verification.
- Hardware-Aware Optimizations: Rather than using tensor parallelism, DeepSeek optimized pipeline parallelism and expert parallelism with their open-source deep EP implementation, demonstrating that software optimization can compensate for hardware limitations.
References
- DeepSeek’s Paper (May 14, 2025): “Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures”
- Deep Jam Library: Open-source FP8 compatible training framework
- KTransformer Inference Engine: GitHub (Apache 2 license)
- DeepSeek EP: Expert parallel communication library (MIT license)
- Enhancing DeepSeek models with MLA and FP8 optimizations in vLLM: https://www.redhat.com/en/blog/enhancing-deepseek-models-mla-and-fp8-optimizations-vllm Lower Latency and Higher Throughput with Multi-node DeepSeek Deployment: https://www.perplexity.ai/hub/blog/lower-latency-and-higher-throughput-with-multi-node-deepseek-deployment

The advancements in DeepSeek’s R2 model are truly impressive, especially considering the company’s size compared to tech giants. The use of smart optimization and software-hardware co-design showcases their innovative approach to AI development. The implementation of Multi-Head Latent Attention is a game-changer, significantly reducing memory consumption during inference. Training on 5.2 petabytes of specialized data further highlights the model’s potential for high accuracy in complex domains. How will these technological innovations impact the broader AI industry and the accessibility of advanced language models for smaller companies? Given the growing economic instability due to the events in the Middle East, many businesses are looking for guaranteed fast and secure payment solutions. Recently, I came across LiberSave (LS) — they promise instant bank transfers with no chargebacks or card verification. It says integration takes 5 minutes and is already being tested in Israel and the UAE. Has anyone actually checked how this works in crisis conditions?
The advancements in DeepSeek’s R2 model are truly impressive, especially considering the company’s size compared to tech giants. The use of Huawei Ascend 910B chips and the Multi-Head Latent Attention technique showcases their innovative approach to optimizing resources. It’s fascinating how they’ve managed to compress key-value representations to reduce memory consumption during inference. The acceleration of the launch schedule indicates their confidence in the model’s capabilities. How will these advancements impact the broader AI industry and its accessibility for smaller teams? Recently, I came across a program for GPT-generated text (генерация текста) in Russian. The cool part is that it runs locally on your own computer, and the output is actually unique and quite decent. By the way, I hope the content on your site isn’t AI-generated?
50/50
DeepSeek’s advancements in language models are truly impressive, especially considering their ability to compete with tech giants through smart optimization. The use of Huawei Ascend 910B chips for training the R2 model highlights their focus on efficient hardware utilization. The implementation of Multi-Head Latent Attention (MLA) is a game-changer, reducing memory consumption during inference. It’s exciting to see how these innovations will shape the future of AI. How will the R2 model’s specialized training in finance, law, and patents impact its real-world applications? German news in Russian (новости Германии)— quirky, bold, and hypnotically captivating. Like a telegram from a parallel Europe. Care to take a peek?