

Introduction
This article explores the evolution of AI beyond language models toward more comprehensive “World Foundation Models” that can understand and interpret actions in visual data. Recent research from Harvard University, Google DeepMind, MIT, IBM, and Hong Kong University of Science and Technology focuses on developing AI systems that can understand context-invariant actions across different video scenarios.
Adaptable World Foundation Models in AI: The New Foundation Model Paradigm
What Are AI World Foundation Models?
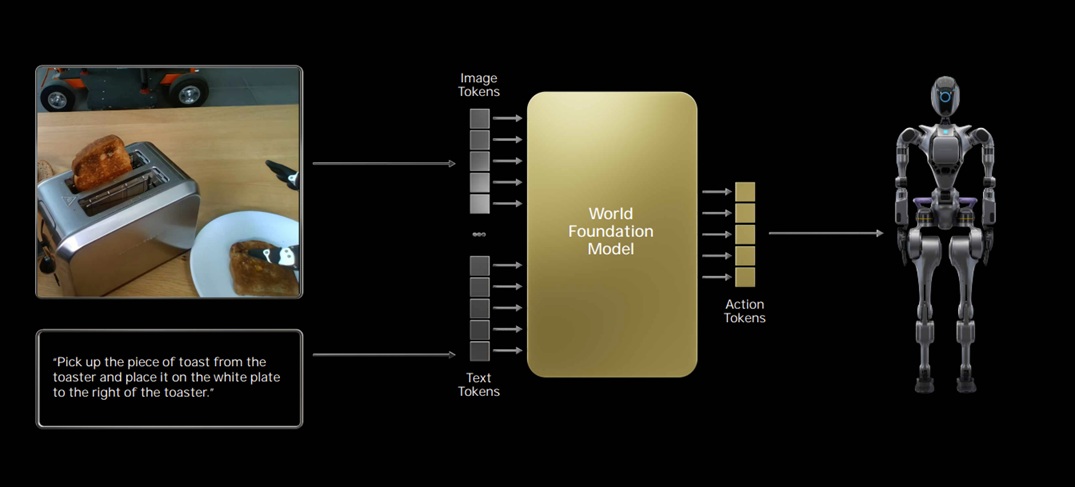
World Foundation Models represent the next evolution in AI, moving beyond language-only models (LLMs) to develop comprehensive systems that understand and interact with the world through multiple modalities. These models aim to create a unified understanding of actions, visuals, and context across different scenarios.
Unlike LLMs that operate primarily on text, World Foundation Models process and understand:
- Visual information and video content
- Actions and physical movements
- Context transfers between different scenarios
- Temporal relationships and predictions
Key Components of Adaptable World Foundation Models
- Latent Action Representation
At the core of these models is the ability to extract context-invariant actions from visual data. For example, the action of “picking up an object” can be understood as the same fundamental action whether someone is picking up a pencil, a glass of water, or a coffee cup.
The models encode these actions in a latent space that represents the abstract concept of the action, separate from the specific objects or context. - Continuous vs. Discrete Action Spaces
Recent research explores two approaches:- Discrete action spaces (like in Nvidia’s N1 model): Actions are quantized into specific categories
- Continuous action spaces (like in the “Other World Learning” research): Actions exist on a continuous spectrum, allowing for more nuanced representation
- Autoregressive Prediction
These models can predict future states based on current observations and extracted actions. For example:- Given a video frame showing a hand approaching a pencil on a table
- And an action vector representing “lift up from table”
- The model can generate the next frame showing the hand holding the pencil slightly above the table
Technical Implementation
Two-Step Process
- Latent Action Auto-encoder:
- Input: Video frames at time T and T+1
- Process: Encode the action occurring between frames into a vector representation
- Output: A latent action vector (e.g., “jump vector”)
- Diffusion-Based World Model:
- Uses the extracted latent actions as conditions
- Pre-trains an autoregressive world model
- Enables prediction of future states based on current observations and actions
Example in Practice
Imagine a video game character jumping:
- The model observes a frame of the character standing and a frame of the character in mid-air
- It encodes this as a “jump” action in latent space
- Given a new frame of the character standing, plus the “jump” action vector
- The model can generate a realistic prediction of what the next frame should look like
Real-World Applications
These adaptable world models enable numerous applications:
- Robotics: Robots can learn transferable skills by understanding actions independent of specific objects
- Video Understanding: Systems can anticipate what will happen next in videos, useful for security monitoring or content analysis
- Game Development: AI can generate realistic responses to player actions across different game environments
- AR/VR: Enhancing mixed reality experiences with predictive physics and interactions
- Healthcare: Analyzing movement patterns for physical therapy or monitoring patient activities
Example: Transferable Action Learning
Consider a robot trained to pick up objects:
Traditional approach: The robot needs separate training for picking up cups, pens, books, etc.
With adaptable world models: The robot learns the abstract “pick up” action once, then applies it to any object without additional training. This works because:
- The latent action space captures the essence of “picking up”
- The diffusion model can generate appropriate predictions for new objects
- The representation is context-invariant
Current Research Landscape
Major players in this field include:
- Nvidia (N1 model with LAPA – Latin Action Representations Space)
- Harvard University, Google DeepMind, MIT, IBM, and Hong Kong University (“Other World Learning” research)
- Stanford University and University of Toronto (reasoning from latent sources)
Most models utilize some combination of:
- Transformer architectures (like Genie by Google DeepMind)
- Variational auto-encoders
- Diffusion models
- Flow matching techniques
Video about WFM
Summary of the above video
Foundation Model Evolution
The video begins by explaining how AI is “breaking free” from language-only models (LLMs) to develop a more comprehensive understanding of the world. The presenter references Nvidia’s N1 model as a recent example of a world foundation model that uses Latin Action Representations Space (LAPA) with vector quantized auto-encoding, and explains how flow matching techniques are used to train diffusion transformers to generate necessary actions.
Technical Approach
The presenter outlines a two-step approach used in the research paper “Other World Learning: Adaptable World Models with Latent Actions” (March 24, 2025):
- Latent Action Auto-encoder: Using variational auto-encoders (VAEs) with a beta factor from 2017, this component extracts context-invariant actions from unlabeled videos, creating a continuous latent action representation space. Unlike Nvidia’s N1 which uses discrete action approaches, this research focuses on continuous latent space.
- Autoregressive World Model: The model conditions predictions on latent actions, enabling fine-grained frame-level control. It employs a diffusion-based framework that can generate high-quality predictions by transferring actions between different video contexts.
Architecture and Implementation
The research utilizes the Genie architecture from Google DeepMind (February 2024), featuring special temporal attention, spatial attention, and feed-forward layers in a spatial-temporal transformer block configuration. The presenter explains that the goal is to extract transferable actions—like “picking up an object”—that can be applied across different contexts regardless of what the specific object is.
Reflections on AI Development
The presenter concludes with a philosophical reflection on AI development approaches, questioning whether the industry needs to train world foundation models on all available social media and video content, or if more targeted, intelligent approaches might be more effective. They express concern about potentially wasting years on inefficient development paths as happened with language models.
Future Directions and Considerations of the new model
As these world foundation models evolve, several questions emerge:
- Data Requirements: Do we need to train on all available video content, or can we be more selective and efficient?
- Computational Efficiency: How can we make these complex models more accessible?
- Transfer Learning: How far can we push the boundaries of context transfer?
- Multimodal Integration: How do we combine understanding across vision, language, touch, and other senses?
These adaptable world models represent a significant step toward AI systems that can truly understand and interact with the world in ways that more closely resemble human understanding, moving well beyond the capabilities of language-only models.
Conclusion
World Foundation Models represent a significant step forward in AI’s ability to understand and interact with the physical world. By extracting context-invariant actions and enabling transfer learning across different scenarios, these models are bringing us closer to AI systems that can understand the world more like humans do—recognizing patterns, predicting outcomes, and adapting to new situations without extensive retraining. As research continues to advance, we can expect these models to become increasingly sophisticated, potentially serving as the foundation for more capable and flexible AI systems across numerous domains.
Key Takeaways
- AI is evolving beyond language-only models to understand actions and visual data
- The latest research uses continuous latent action representation to model actions in videos
- Context-invariant actions allow AI to transfer learning across different scenarios
- The approach combines variational auto-encoders with diffusion models
- Code for this research is publicly available on GitHub under Apache 2 license
- The presenter encourages a more thoughtful approach to AI development instead of simply processing more data
Related References
- MIT computer science class 6.S184 on generative AI with stochastic differential equations
- Stanford University and University of Toronto’s work on reasoning from latent sources
- Nvidia’s N1 model and LAPA (Latin Action Representations Space)
- Google DeepMind’s Genie architecture (2024)
- Research paper: “Adaptable World Models with Latent Actions” (March 24, 2025)
