

Introduction
This video explores groundbreaking research from UC Berkeley about task vectors in Vision Language Models (VLMs) and their cross-modal capabilities. The presentation uses a Halloween theme to discuss what the presenter calls “spooky action” in artificial intelligence, drawing a parallel to Einstein’s “spooky action at a distance” concept.
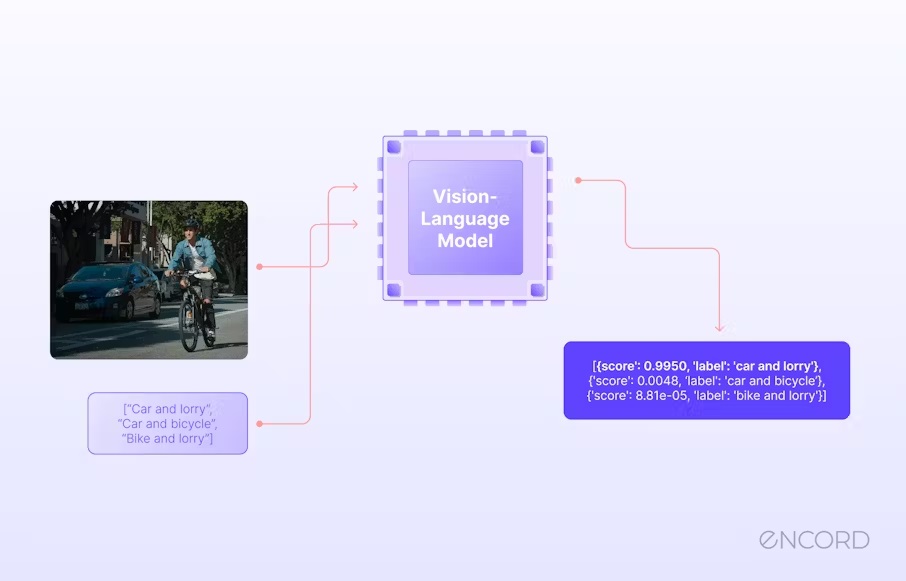
What are Vision Language Models (VLMs)?
- Multimodal Learning: VLMs are a type of artificial intelligence that can process and understand both visual and textual information. This is achieved through a single model that learns from both images and their corresponding text descriptions.

- Bridging the Gap: VLMs bridge the gap between computer vision and natural language processing (NLP). They enable machines to not only recognize objects and scenes in images but also understand the context and meaning behind them.
How do VLMs work?
- Embedding: Both images and text are transformed into numerical representations (embeddings) that the model can process.
- Joint Learning: The VLM learns to associate visual features (like shapes, colors, and textures) with textual concepts (like objects, actions, and relationships).
- Multimodal Understanding: The model can then perform tasks that require understanding both visual and textual information, such as:
- Image Captioning: Generating descriptive text for an image.
- Visual Question Answering: Answering questions about an image.
- Image Search: Finding images based on a textual description.
- Text-to-Image Generation: Creating images based on a text prompt.
Key Architectures
- CLIP (Contrastive Language-Image Pretraining): Learns by comparing pairs of images and text descriptions.

- ALIGN (ALigning Language and Images): Learns by aligning image regions with their corresponding words in a sentence.
- BLIP (Bootstrapping Language Image Pretraining): Uses a generative approach to generate text descriptions for images

Applications
- Search: Enhancing image search by understanding the context of the query.
- Accessibility: Generating descriptions for images to aid visually impaired users.
- Robotics: Enabling robots to understand and interact with the environment.
- Medical Imaging: Analyzing medical images and generating reports.
- Content Creation: Assisting in tasks like generating captions, writing product descriptions, or creating marketing materials.
Challenges and Future Directions
- Data Quality: The quality of training data is crucial for the performance of VLMs.
- Model Complexity: VLMs are often large and computationally expensive to train.
- Bias and Fairness: VLMs can inherit biases present in the training data.
- Multimodal Understanding: Further research is needed to improve VLMs’ ability to understand complex relationships between visual and textual information.
Video Discuss talk about the VLM including Spooky Action:
Key Research Context as in the video above
Historical Background
- References Google DeepMind’s study on in-context learning (ICL) from approximately one year ago
- Introduces the concept of task vectors as compressed representations of few-shot demonstrations
- Discusses how ICL can be compressed into single task vectors that modulate transformer behavior
Recent Developments
- February 2024: Research on function vectors in large language models
- October 7, 2024: UC Berkeley/Google Research findings on visual task vectors in VLMs
- October 29, 2024: UC Berkeley’s latest research on cross-modal task vectors
Technical Analysis
Task Vector Architecture
- Task vectors operate in high-dimensional space (1000-2000 dimensions)
- Initial layers (4-5) of transformer encode mapping rules from demonstrations
- Task vectors are patched at specific layers (e.g., layer 12) during forward pass
- Query processing occurs separately from task vector computation
Cross-Modal Capabilities
- Multiple Input Modes:
- Visual in-context learning (e.g., flag images paired with capitals)
- Textual instructions
- Pure text examples
- Mixed vision and text inputs
- Shared Representation:
- Similar tasks cluster together in embedding space regardless of input modality
- High cosine similarity (0.95) between LLM and VLM task vectors
- Enables cross-modal task transfer
Performance Analysis
Layer Distribution Patterns:
- Country-capital tasks: Late task vector emergence and answer generation
- Food-color tasks: Earlier and more stable pattern
- Food-flavor tasks: Extended processing time, less certain answers
Technical Implementation Details
- Fine-tuning Considerations:
- Full fine-tuning used instead of LoRA
- Questions raised about adapter-based approaches
- Importance of maintaining vector composition in high-dimensional space
- Layer-specific Behavior:
- Layer 0: High input probability
- Layer 18: Peak task vector representation
- Layer 25-28: Answer generation
Key Findings
- Cross-modal Task Vector Transfer:
- Task vectors from text can inform image queries
- Text ICL vectors outperform image-based ICL baselines
- Suggests text is more stable for encoding task vectors
- Unified Task Representation:
- Single task vector can handle multiple input modalities
- Resource-efficient processing of similar tasks
- Enhanced multimodal adaptability
Conclusion
The research demonstrates a significant advancement in understanding how VLMs and LLMs process and transfer knowledge across modalities. The discovery of cross-modal task vectors suggests a more unified and efficient approach to multimodal AI systems, where tasks can be represented and transferred across different input types.
Key Takeaways
- Task vectors exist in both language and vision models
- Cross-modal transfer is possible and effective
- Text-based task vectors show superior performance
- Unified task representations can enhance AI system efficiency
- Full fine-tuning currently shows better results than parameter-efficient approaches
